公众号记得加星标⭐️,第一时间看推送不会错过。
来源:内容编译自semiengineering。
半导体封装的下一个重大飞跃将需要一系列新技术、新工艺和新材料,但它们将共同实现性能的数量级提升,这对于人工智能时代至关重要。
并非所有这些问题都已得到彻底解决,但最近的电子元件技术大会 (ECTC) 让人们得以一窥自 ChatGPT 的推出震惊科技界以来,过去几年中取得的巨大进步。AMD、台积电、三星、英特尔以及众多设备供应商详细介绍了混合键合、玻璃芯基板、微通道冷却或直接冷却以及背面电源方案散热等方面的改进。
AMD 高级副总裁兼企业研究员 Sam Naffziger 在一次关于人工智能计算的演讲中表示:“人工智能改变超级计算机/高性能计算领域的方式令人惊叹。” ChatGPT 和 Gemini 吸收了整个互联网数据并用于训练模型,但高质量的文本数据已被完全消耗。人工智能变得更加智能的方式是通过所谓的训练后测试时计算(或思维链推理)的方法。在这一过程中,模型相互检验,生成合成数据并迭代响应,最终产生更周全的结果。尽管每一次智能的提升都具有巨大的价值,但要获得智能的线性回报,计算量需要增加两到三个数量级。因此,对计算的需求将持续增长,而这会导致成本下降,而这正是我们行业非常擅长的。我们改进制造工艺,产量越来越大,良率也越来越高,成本也越来越低。随着这一趋势的持续,芯片制造——尤其是封装——的创新将发挥核心作用。
ECTC 详细介绍的主要进展包括:
英特尔的混合键合间距可低至 1µm;
台积电直接冷却CoWoS,包括4个SoC和6个HBM;
ITRI/Brewer Science 的具有聚合物/铜混合键合的 10 层 RDL;
佐治亚理工学院的芯片作为冷却剂,通过 TSV/硅柱进行液体冷却;
Corning/Fraunhofer IZM 用于光收发器的玻璃波导;
三星用于移动处理器和 DRAM 的铜基散热块,以及
Imec 的热点热通量 3D 多芯片模拟。
热芯片的液体冷却
随着强制风冷技术达到极限,芯片级液体冷却技术正在初具规模。“我们设法用高速风扇冷却高达 1,000 瓦的设备,风扇功耗约占服务器机架预算的 20%,而 I²R损耗则占 10% 到 20%,”Naffziger 说道。“所以现在我们有 40% 的电力仅用于输送电流和散热。这显然不是构建高效计算系统的方法。这就是推动直接液体冷却不断升级的原因,虽然泵和冷凝器会产生一些电力开销,但比带有大型散热器的高速风扇要低得多。”
在此次会议上,台积电的连宇仁介绍了一种名为硅集成微冷却器 (IMEC-Si) 的液冷架构,目前正在使用有机中介层 (CoWoS-R) 上 1.6 倍光罩大小的测试平台进行可靠性测试。该冷却器设计用于模拟 4-SoC、8-HBM 封装,在 10 升/分钟的 40°C 水流条件下,可实现超过 3,000 瓦的均匀功耗。连宇仁表示,与采用热界面材料的间接液冷板方案相比,这种液冷方案可提供更优异的冷却效果(功率密度高达 2.5 W/mm²)。
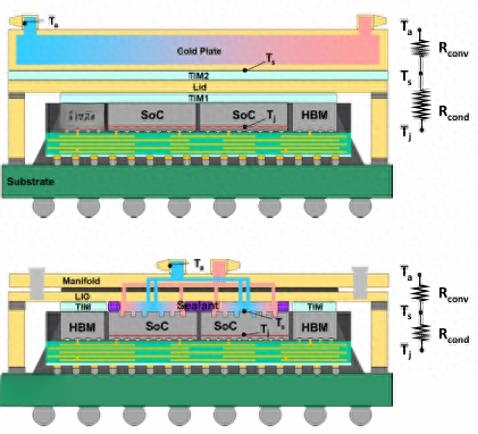
图 1:采用 10 升/分钟水流的直接液冷 CoWoS(下图)比采用 TIM、盖板和冷板配置的 CoWoS 散热更多
台积电的组装流程在SoC背面的铜柱阵列上覆盖一层保护层。将组件翻转到载体晶圆上,然后进行C4凸块工艺。翻转并去除保护层后,按照传统的CoWoS流程,在SoC周边点涂弹性密封剂。密封剂可最大程度地减少翘曲,并密封芯片到盖板的区域。“回流焊后,将一个具有单入口和单出口的歧管组装到集成系统上,该歧管的设计旨在使多个冷却隔室之间的流量均匀分布。”
台积电的3.3X光罩测试平台搭载4个SoC和6个HBM芯片,其翘曲范围达到160-190微米,导致盖板和SoC芯片之间的流速和分布发生变化。该封装已通过氦气泄漏测试和早期可靠性测试。
芯片直接冷却的需求如此迫切,以至于佐治亚理工学院提出了一个新概念——芯片作为冷却剂。佐治亚理工学院3D封装集成中心主任Muhannad Bakir表示:“想象一下,我们设计的芯片成为现成的开源社区的一部分,它们具有不同的冷却能力,比如不同的直径、间距,以及不同的TSV设计。我们可以在该结构中构建独特的TSV结构、独特的冷却结构以及其他独特的功能,以促进热量和功率的传输。因此,它实际上只是堆栈中的混合键合解决方案。” Bakir的团队展示了采用5nm TSV的硅制成的微鳍针状散热器(见图2),其冷却能力可超过300W/cm²。

图 2:微流体冷却包括带有硅通孔的硅散热器,用于实现芯片间连接
三星针对移动应用的新型架构中,另一种冷却方法是将加热块放置在应用处理器的顶部(见图 3)。[3] Kyung Don Mun 及其同事探索了一种不对称的内存和处理器结构,该结构为处理器、内存和铜基散热块的放置提供了设计灵活性。
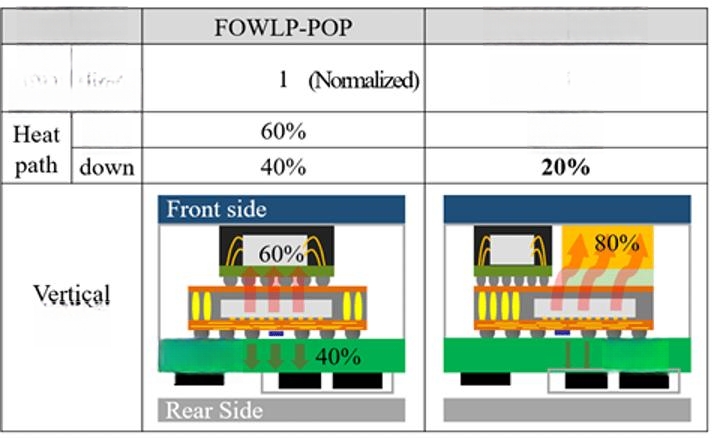
图 3:将逻辑结构上的对称存储器(左)转换为处理器上方带有铜散热块的非对称结构(右),可以改善带有背面供电网络的 2nm 环栅逻辑器件的散热效果
该应用处理器的2nm环绕栅极晶体管结构采用背面供电网络,要求通过模块的散热性能提高20%。三星使用Ansys有限元模型识别高风险区域并模拟翘曲。“RDL图案设计优化对于这种异构封装设计尤为重要,因为薄RDL容易受到热机械应力集中和裂纹故障的影响,”Mun说道。选择图案宽度更宽、图案长度更长的重分布层可以减少翘曲。成型材料、双面RDL和热界面材料也得到了进一步改进,以提高导热性和散热效果。
混合键合
细间距多层有机重分布层 (RDL) 作为硅中介层和层压基板的可行替代方案,正日益受到关注。这一转变源于 RDL 能够以低成本提供高速互连。工研院 (ITRI) 和Brewer Science展示了一种五层堆叠结构,采用聚合物/铜 RDL 进行铜-铜混合键合,旨在实现高速数字应用中的高输入/输出 (I/O)、低回波损耗和低插入损耗。
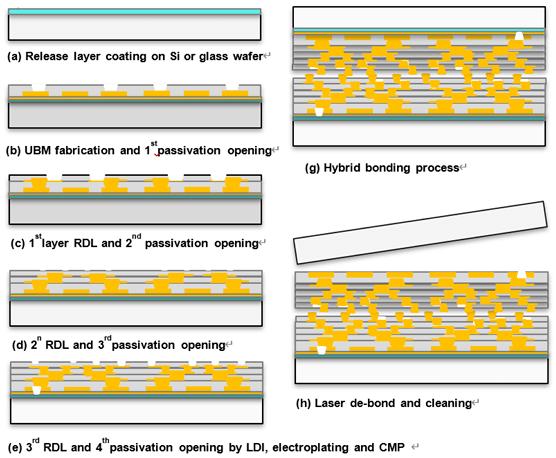
图 4:聚合物/铜层重新分布后,进行可控翘曲的 Cu-Cu 混合键合
在玻璃载体晶圆上构建线/间距RDL(4至10µm L/S)后,使用负性光刻胶和i线曝光对低k聚合物(2.5)进行图案化,随后进行蚀刻,用钛阻挡层和铜填充焊盘,最后通过铜CMP进行平坦化。混合键合采用300°C(1.06 MPa)的热压键合,随后使用紫外激光对载体晶圆进行剥离。聚合物具有低模量、高热稳定性和低吸湿性的特性,有助于降低多层RDL堆叠的翘曲。
近年来,采用传统电介质(SiO2 基/铜)的混合键合的间距微缩已从 10µm(制造工艺)微缩至 1µm(研发工艺)。英特尔高级首席工程师 Adel Elsherbini 及其同事探讨了实现此类微缩所需的一些功能。
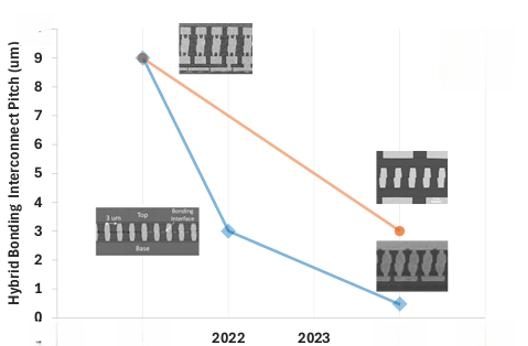
图 5:英特尔采用混合键合的研究成果
他们的论文指出,系统架构通常决定了选择晶圆间 (W2W) 还是芯片间 (D2W) 键合。晶圆间键合的主要限制在于它需要相同尺寸的芯片键合。该技术更加成熟,可以实现更精细的间距。芯片间键合没有尺寸限制,并且只使用已知良好的芯片。“对于 C2W 应用,随着 HB 间距继续缩小到 1μm 甚至更小,贴装精度要求突破了当前一代芯片键合机的极限。为了确保电气连续性,整个芯片区域需要达到相同的精度水平,精确到几十纳米。芯片内精度控制(类似于 W2W 键合的跳动和变形控制)变得越来越重要。”作者表示。
传统的贴装精度标准,例如芯片中心或最差边角错位,已不再足够。D2W工艺控制在键合过程中变得越来越复杂,更加注重每个芯片级的翘曲控制、芯片整形和键合波传播控制。另一方面,为了量化芯片内键合精度,需要新的对准标记策略和更完善的键合后精度测量方法,以了解从芯片准备到键合过程中芯片级的变形行为。作者指出,红外脱键技术可以重复使用硅载体晶圆,从而降低拥有成本。
利用背面供电散热
背面供电是一种新颖的互连方案,它在晶圆背面构建供电网络,从而显著降低晶体管供电相关的电压降。晶圆正面的互连线仅用于传输信号,从而带来诸多电气优势。
然而,相对于标准互连堆栈,这种新方法加剧了热点问题。“如果从正面来看,晶体管产生的所有热量都会直接进入硅片,到达散热器或冷板,”IBM研究院高级技术人员Dureseti Chidambarrao说道。“但还有一个不太好的情况,那就是背面供电——因为你将电源与信号分离,所以这是一种更简单的实现方法——但我们现在面临的挑战是如何将这种堆栈中的热量散发出去,因为热尖峰和热电路会被困住。”

图6:由于有源器件被夹在金属堆栈之间,背面供电会引发新的热流模式
IBM 开发了一个各向异性模型,用于精确计算后端堆栈的传热,该模型考虑了材料特性。该 AI 模型将设计与互连堆栈中的局部功率密度、工作负载和材料特性紧密关联。“你获取 GDS 文件,它实际上会同时计算多个层级和多个层面的平均特性,从而在每个给定位置获得正确的(传热)平均特性。现在,你可以为每个区块计算,并且可以进一步优化,”Chidambarrao 说道。
在设计阶段纳入此类散热考虑的重要性怎么强调也不为过。“封装和芯片相互作用,并且耦合非常紧密,因此这是一个完整的系统技术优化问题,你必须在设计中考虑散热问题,”他说道。“尤其对于背面电源来说,这一点至关重要,我甚至还没想过最糟糕的情况——把背面电源放在3D芯片上。如果这就是你想要做的,那么解决方案显然要严格得多。”
背面供电技术已应用于芯片设计中。“我们预计明年将首次在产品中实现背面供电,”imec首席技术人员兼热建模和特性研发团队负责人Herman Oprins表示。“虽然背面供电最初是一种无源结构,但未来也将用于信号时钟和其他功能。方法多种多样,但关键在于需要通过纳米硅通孔(nanoTSV)连接正面和背面。”
纳米硅通孔 (NanoTSV) 要求硅厚度至少减薄至 300 纳米,甚至可能小于 100 纳米。此外,需要进行详细的建模,以了解此类器件的冷却需求。
奥普林斯说:“如果存在局部热点和超薄硅片,温度实际上会上升,因为用于散热的电容量(硅片)更少。另一方面,由于背面有金属叠层,这种致密的金属阵列可能有助于设备的散热。”
Imec 此前已证明,实施背面供电会导致 10% 至 30% 的热损失(ECTC 2024)。今年,Oprins 团队利用背面供电网络 (BSPDN) 模拟了逻辑堆叠在内存上或内存堆叠在逻辑上的热效应。这些模拟包括芯片的正面对正面混合键合和背面对正面键合,结合使用了玻尔兹曼传输方程和蒙特卡洛模拟。模拟结果显示了芯片均匀加热和热点影响之间温升的差异(见图 7)。
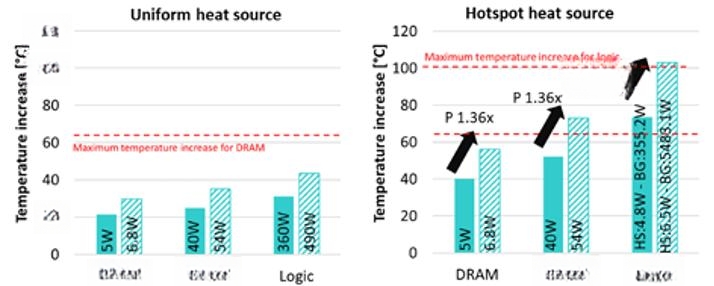
图 7:均匀加热的器件温度升高情况(左)与增加热点的器件温度升高情况
“堆栈中逻辑和存储器芯片的顺序对热性能的影响更大,”Oprins 表示。“逻辑芯片位于顶层,由于靠近冷却系统,逻辑芯片温度较低,但由于堆栈中存在较高的热耦合,存储器温度较高。” 多层存储器位于逻辑芯片上表明,BSPDN 的热影响比多芯片堆叠有所降低。在这种情况下,逻辑芯片位于顶层的配置受存储器芯片温度的热限制,而对于存储器位于顶层的配置,逻辑芯片温度是限制因素。该论文总结道:“更高效的冷却系统显著提升了 3D SoC BSPDN 的热性能,从而实现了逻辑芯片位于存储器上的配置并实现了校准的功耗。” [7]
奥普林斯强调了液体冷却的重要性。“以3D架构为例,如果堆叠5个芯片,每个芯片的功耗假设为100瓦,并使用传统的空气冷却,那么最终的最高结温将远高于500°C,”奥普林斯说道。“如果集成一块冷却板,最高结温将达到250°C左右。但是,如果能在堆栈内部开发层间冷却技术,那么就有机会将温度降至50°C左右。” 根据imec的3D堆栈模拟结果。
共封装光学器件
业界对更快数据网络和设备接口速度的需求正在急剧增长。数据中心机架内部的一个关键推动因素是将光学引擎与 GPU 和 HBM 集成到同一个封装中。ASE 研究员 CP Hung 表示:“借助共封装光学器件 (CPO),我们有机会将电气互连和光学连接集成在一个封装中。这是业界的一个新里程碑。通过将光学引擎更靠近处理器,我们将每根光纤的传输速度从 200 Gb/s 提升到 6.4Tb/s,带宽提高了 32 倍。”
尽管CPO前景光明,但仍存在未知数。“CPO肯定会实现,而且势头肯定会推动它尽快实现,”ASE工程、营销和技术推广高级总监Mark Gerber表示。“CPO在热方面和翘曲方面都存在敏感性。重要的是,业界希望保留光学引擎现有的可插拔(即可更换)特性。然而,虽然可插拔特性易于切换,但掌握起来却并不容易。”
在 ECTC 上,ASE 展示了其用于 ASIC 交换机和以太网/HBM 共封装光学平台的模块化平台。
热模拟在选择先进封装中散热堆栈的架构、工艺和材料方面也发挥着关键作用。“从历史上看,在单片芯片集成中,封装设计和散热器的热模拟是在‘通过/不通过’的基础上进行的,” Amkor Technology热模拟首席工程师 Tom Nordstog 表示。对于多芯片组封装,模拟在封装设计早期发挥着更为显著的作用。“热模拟是一种风险/回报练习,用于选择最终设计。理想情况下,封装的热设计在芯片设计确定之前进行。我们看到最积极的客户在这些早期阶段就加入了热模拟。”
康宁研发中心的 Lars Brusberg 表示,康宁和 Fraunhofer IZM 提出了一种可扩展的“平面二维波导电路,通过减少对光纤电缆端接和手动组装的需求,可以降低未来几代 CPO 解决方案所需的空间、复杂性和成本”。[8] 该团队使用 460 x 303 毫米熔融成型玻璃面板,制造了单模板级互连,其波导布局旨在满足从面板到 CPO 模块的 1024 条光链路的连接要求,用于 102.4 Tb/s 数据中心交换机应用。Fraunhofer IZM 工程师设计了工艺流程(见图 8),其中包括热离子交换工艺,将单模波导集成到玻璃中,与 1310nm 波长的单模光纤的光模式匹配。移除掩模后,执行第二个反向离子交换工艺步骤,将波导芯埋入玻璃表面以下,以减少传播损耗。
“为了实现与玻璃波导面板的光纤连接,我们组装了MPO-16适配器,并将玻璃波导电路集成到1U机架底盘中,以展示其仅为0.7毫米的纤薄外形,”Brusberg说道。这种新颖的方法有望为基于PCB的光收发器铺平道路。

图 8:工艺流程包括金属沉积、光刻胶涂覆、波导成像和离子交换,使银扩散到图案中
参考链接
https://semiengineering.com/novel-assembly-approaches-for-3d-device-stacks/
*免责声明:本文由作者原创。文章内容系作者个人观点,半导体行业观察转载仅为了传达一种不同的观点,不代表半导体行业观察对该观点赞同或支持,如果有任何异议,欢迎联系半导体行业观察。
END
今天是《半导体行业观察》为您分享的第4081期内容,欢迎关注。
加星标⭐️第一时间看推送,小号防走丢

