时间序列异常检测是金融监控、网络安全防护、工业制造控制以及物联网系统监测等领域的核心技术问题。本文研究了一种结合深度学习LSTM自编码器与KMeans聚类算法的无监督异常检测方法,该方法首先利用LSTM自编码器学习序列数据的潜在表示,然后在潜在空间中应用KMeans聚类实现异常模式的自动识别。
本文基于Numenta异常基准(NAB)数据集进行实验验证,该数据集是时间序列异常检测领域的标准评估基准,包含多种真实场景的时间序列数据。
数据集介绍
Numenta异常基准(NAB)是一个综合性的时间序列异常检测评估框架,涵盖了工业测量传感器数据、真实网络流量监控数据、在线广告交换系统数据以及合成生成的模拟数据等多个应用领域的时间序列样本。
本文选用NAB数据集中的artificialWithAnomaly子集作为实验数据。该子集包含人工合成的时间序列数据,其中注入了预定义的异常模式,为无监督异常检测算法的有效性验证提供了理想的测试环境。数据集的每条记录由时间戳和对应的数值组成,模拟了实际应用场景中的监测指标变化。

在深入分析核心算法之前,需要明确序列数据的基本概念以及LSTM自编码器在异常检测中的应用原理。
序列数据的特征与挑战
序列数据,也称为时间序列数据,是指按照时间顺序采集和记录的数据序列。这类数据的显著特征在于观测值之间存在时间依赖关系,当前时刻的数值往往与历史时刻的观测值密切相关,因此时间维度的信息对于数据分析具有关键意义。序列数据广泛存在于物联网传感器监测、金融市场价格波动、信息系统日志记录等应用场景中。由于序列数据包含复杂的时间演化模式,传统的机器学习方法在处理此类数据时存在明显局限性。相比之下,具备时间动态建模能力的深度学习模型是长短期记忆网络(LSTM),能够有效捕获和利用时间序列中的长期依赖关系。
LSTM自编码器的异常检测机制
LSTM自编码器与用于序列预测或分类的标准LSTM网络在架构设计上存在本质差异。LSTM自编码器的核心目标是学习输入序列的重构映射,其架构由编码器和解码器两个主要组件构成。编码器LSTM网络负责将输入的时间序列压缩为低维的潜在表示向量,该向量捕获了序列数据的核心特征信息。解码器LSTM网络则从这个压缩的潜在编码中重构原始的输入序列。
异常检测的基本假设是,模型在正常数据上训练后,能够准确重构符合正常模式的序列,而对于偏离正常行为的异常序列,其重构质量会显著下降。通过分析重构误差的分布特征或潜在空间中的结构模式,可以有效识别时间序列中的异常行为。
当LSTM自编码器将输入序列映射为潜在向量后,这些向量构成了一个新的特征空间,其中包含了原始数据的时间模式信息。在这个潜在空间中,正常序列和异常序列可能表现出更明显的分离特征。本方法不仅依赖重构误差进行异常判断,还在潜在空间中应用KMeans聚类算法对相似的潜在表示进行分组。该策略基于以下假设:正常序列的潜在表示会聚集形成主要的聚类簇,而异常序列则表现为离群点或形成规模较小的独立聚类。这种方法能够检测出那些可能不会产生显著重构误差,但在潜在空间中展现出不同时间动态特征的细微异常模式。
现在让我们深入分析具体的实现过程。
数据探索与可视化
首先对数据进行可视化分析,了解时间序列的基本分布特征:
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
plt.figure(figsize=(12,6))
sns.lineplot(x=df.index, y=df['value'])
plt.show()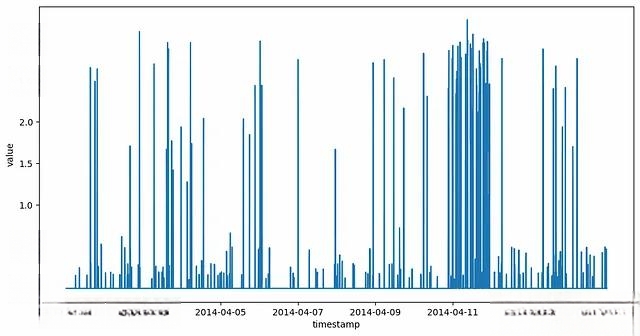
sns.histplot(df['value'], bins=100, kde=True)
数据预处理与序列构造
在确认数据格式的正确性后,使用MinMaxScaler对时间序列进行标准化处理,并构造固定长度的滑动窗口序列作为LSTM网络的输入。该预处理步骤对于深度学习模型的训练稳定性和收敛性具有重要意义。
scaler = MinMaxScaler()
scaled_data = scaler.fit_transform(df[['value']])
def create_sequences(data, seq_length):
X = []
for i in range(len(data) - seq_length):
X.append(data[i:i + seq_length])
return np.array(X)
SEQ_LENGTH = 50
X = create_sequences(scaled_data, SEQ_LENGTH)LSTM自编码器模型构建
构建LSTM自编码器的网络架构,其中编码器将输入序列压缩为64维的潜在向量,解码器则尝试从该潜在表示重构原始序列:
input_dim = X.shape[2]
timesteps = X.shape[1]
inputs = Input(shape=(timesteps, input_dim))
encoded = LSTM(64, activation='relu', return_sequences=False, name="encoder")(inputs)
decoded = RepeatVector(timesteps)(encoded)
decoded = LSTM(64, activation='relu', return_sequences=True)(decoded)
autoencoder = Model(inputs, decoded)
autoencoder.compile(optimizer='adam', loss='mse')
autoencoder.fit(X, X, epochs=50, batch_size=64, validation_split=0.1, shuffle=True)为了提取序列的潜在表示,定义独立的编码器模型:
encoder_model = Model(inputs, encoded)
latent_vectors = encoder_model.predict(X, verbose=1, batch_size=32) # shape = (num_samples, 64)潜在空间聚类分析
区别于传统的重构误差阈值方法,本文在压缩后的潜在向量空间中应用KMeans聚类算法进行异常检测:
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters=2, random_state=42)
labels = kmeans.fit_predict(latent_vectors)
# 假设样本数量较多的聚类为正常模式
normal_cluster = np.bincount(labels).argmax()
anomaly_mask = labels != normal_cluster通过主成分分析(PCA)将高维潜在空间投影到二维平面进行可视化:
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
latent_pca = pca.fit_transform(latent_vectors)
plt.figure(figsize=(10, 6))
sns.scatterplot(x=latent_pca[:, 0], y=latent_pca[:, 1], hue=labels, palette='Set1', s=50, alpha=0.7)
plt.title("Kmeans cluster in latent space (PCA 2D)")
plt.xlabel("principal component 1")
plt.ylabel("principal component 2")
plt.grid(True)
plt.show()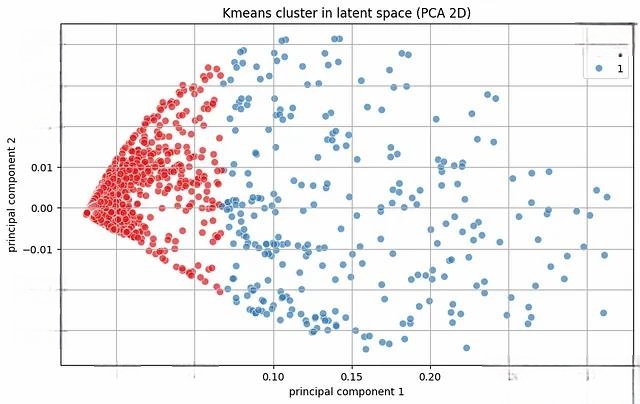
异常检测结果可视化
将检测到的异常点在原始时间序列上进行标注,直观展示异常检测的效果:
timestamps = balancer.index[SEQ_LENGTH:]
plt.figure(figsize=(15, 5))
plt.plot(timestamps, df['value'][SEQ_LENGTH:], label='Value')
plt.scatter(timestamps[anomaly_mask], df['value'][SEQ_LENGTH:][anomaly_mask], color='red', label='Detected Anomalies')
plt.legend()
plt.title("Anomalies Detected via KMeans on LSTM Latent Space")
plt.show()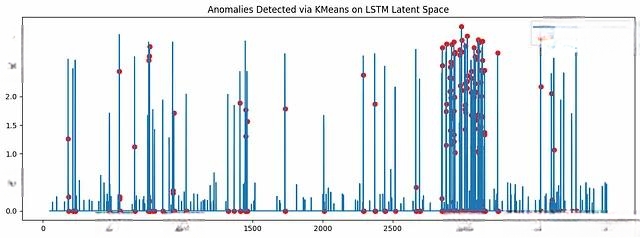
总结
本文提出的基于LSTM自编码器和KMeans聚类的组合方法,通过整合深度学习的序列建模能力与无监督聚类的模式分组优势,实现了对时间序列数据中异常模式的有效检测,且无需依赖标注的异常样本进行监督学习。
该方法具有以下技术优势:首先,完全基于无监督学习范式,无需人工标注的训练数据,适用于缺乏先验异常知识的实际应用场景;其次,能够自适应地学习复杂的时间序列模式,包括长期依赖关系和非线性时间动态;最后,通过潜在空间的分析为异常检测提供了新的视角,支持对数据内在结构的深入探索和可视化分析。
这种方法在工业监控系统、金融风险管理、网络安全监测等对异常检测准确性和实时性要求较高的应用领域具有广阔的应用前景。
作者:Falonne KPAMEGAN
