在科技史上,很多颠覆性的突破,回过头看,其路径都显得如此顺理成章,仿佛是唯一的必然。
比如今天,我们谈论通用人工智能(AGI)时,一个清晰的公式似乎已经摆在面前:让AI先通过“预训练”拥有海量的知识和理解能力,再通过“强化学习”赋予它强大的决策和推理能力。
理解力,加上决策力,一个智能的Agent不就诞生了吗?
这个逻辑听起来天衣无缝。但你是否知道,为了走通这条看似“必然”的道路,行业最顶尖的头脑,曾在黑暗中摸索了近十年,并付出了两次代价高昂的失败。
今天,我想和你分享的,就是这部AI的“隐秘斗争史”。它的主角,是OpenAI。它的剧情,关乎今天所有AI Agent的来龙去脉。
1、第一次失败(2016年):纯粹RL的“头铁”与幻灭
故事要从2016年说起。那一年,AlphaGo点燃了强化学习的火炬,整个AI界为之沸腾。雄心勃勃的OpenAI也发起了一个名为“Universe”的宏大项目,他们的目标在今天看来依然前卫:只用强化学习,让AI学会在真实的网页上独立完成任务,比如,买一张机票。

这听起来和我们今天热议的AI Agent何其相似!
当时的工程师们满怀激情,他们搭建了一个复杂的系统,让AI智能体真的可以在网页上“看见”和“点击”。他们相信,只要有足够多的试错,AI终将能学会从输入“旧金山”到“纽约”,再到点击“确认支付”的全过程。
然而,现实给了他们沉重一击。AI确实可以在某个特定的航空公司网站上,通过成千上万次的训练,像一个熟练工一样背下购票流程。可一旦换一个新的网站,界面稍有不同,它就立刻手足无措,变成了一个“数字白痴”。
问题出在哪?它只有“肌肉记忆”,没有“真实理解”。 它知道在一个固定的棋盘上如何落子,却根本不明白“出发地”、“目的地”这些概念的真正含义。
最终,这个过于超前的项目被悄然关停,团队也被裁撤。OpenAI的第一次Agent探索,宣告失败。

2、第二次失败(2019-2020年):机器人领域的再次碰壁
第一次的失败并没有浇灭OpenAI的热情。他们将目光投向了另一个更具挑战的领域:机器人。
2019年,他们推出了一个惊艳世界的项目:用强化学习训练一只灵巧的机械手,成功复原了魔方。这再次证明了RL在完成复杂、精确任务上的巨大潜力。
乘胜追击的他们,提出了一个更大的目标:让机器人学会整理桌面。这几乎是今天所有具身智能公司都在攻克的难题。

然而,历史再一次重演。在高度可控的仿真环境中,机器人表现出色。可一旦回到混乱、多变的物理世界,面对无穷无尽的物体形态、光照变化和意外情况,纯粹的强化学习再次显得力不从心。
一个连“苹果”和“番茄”都无法稳定识别的AI,你如何能指望它精准地执行“把水果放到篮子里”的决策呢?
2021年,在又一次的碰壁后,OpenAI做出了一个艰难的决定:解散机器人团队。第二次向通用智能发起的冲锋,似乎又一次陷入沉寂。
3、转折点:那块名为“预训练”的拼图
命运的奇妙之处就在于,转机往往出现在意想不到的地方。
就在OpenAI解散机器人团队的同一年,其内部一篇关于多模态模型Clip的研究论文发表了。Clip通过学习海量的“图片-文本”数据对,建立起了强大的视觉和语言的“联合理解”能力。它本身并非为机器人设计。
但华盛顿大学的研究者们敏锐地抓住了这块“拼图”。他们将Clip的“理解能力”与“强化学习的决策能力”相结合,奇迹发生了:一个能听懂人类语言指令(比如“请把那个蓝色的杯子递给我”)并准确执行的机器人诞生了。
至此,那条隐藏在历史迷雾中的通关公式,终于被完整地揭示出来:
预训练大模型 = 通用的理解能力(一个见多识广的大脑)
强化学习 = 高级的决策能力(一个果断行动的小脑)
通用智能 ≈ 理解能力 × 决策能力
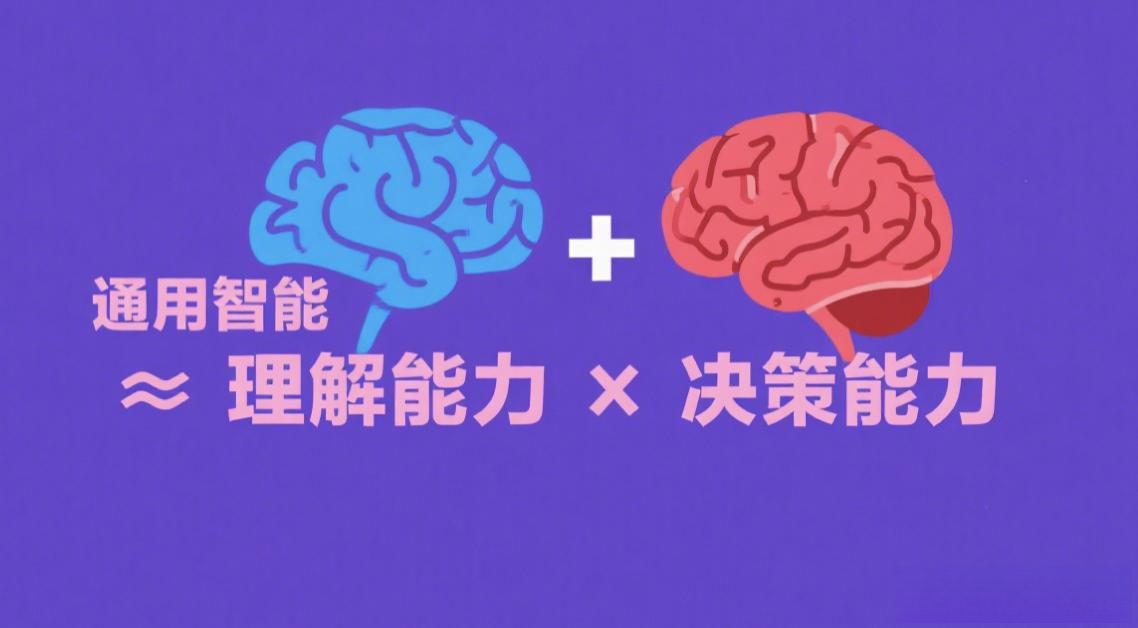
这两者,不是加法关系,而是乘法关系。任何一项为零,结果都将为零。
3、结语:没有白走的路
现在,我们可以回答开篇那个“马后炮”式的问题了。
历史的进程并非一条直线。正是因为OpenAI们在“纯强化学习”这条路上爱过、痛过、失败过,才让整个行业都深刻地认识到,“通用理解能力”是不可或G跳过的前提。当GPT-4这样强大的“大脑”终于出现时,曾经蛰伏的“强化学习”才得以爆发出真正的威力,将“理解”转化为有效的“行动”。
那些看似走不通的弯路,最终都成了通往山顶的台阶。读懂了这段隐秘的斗争史,你才能真正理解,为什么今天我们拥有的一切,既是科技的必然,也是历史的馈赠。
