近期,上海人工智能实验室实习生李明与张凯鹏研究员的团队,探讨了在多模态大模型规则基础的强化学习微调(RFT,Reinforcement Fine-Tuning)中显式思考过程的作用。
该研究揭示了一个具有重要实践意义的发现:以 DeepSeek-R1 为代表的大模型往往需要“先思考再回答”的推理模式,但在简单视觉任务场景下,采用“不思考”强化学习(No-Thinking-RL)策略反而能够显著提高模型的微调效率和性能表现。
这一现象的背后涉及重要的计算资源优化机制。研究发现,与传统监督式微调(SFT,Supervised Fine-Tuning)相比,RFT 会显著增加 GPU 显存需求。
具体表现为:一个原本仅需单张 80G 显存 NVIDIA A100 显卡即可完成的 SFT 任务,而采用 RFT 时可能需要 4 至 8 张同规格显卡才能满足需求。这种显存占用的急剧增加主要源于 RFT 需要并行处理多个较长序列的模型输出。
“不思考”的强化学习模式能够强制模型仅输出精简的最终答案,从而显著降低 GPU 内存占用。张凯鹏对 DeepTech 表示,这种新模式对计算资源相对有限的中小企业或学校实验室具有重要的意义。通过采用这种优化方式,即使仅配备中低端显卡(如 40GB 显存)也能够开展大模型相关的强化学习微调研究,显著降低了研究门槛。
在实际应用场景中,如移动端、自动驾驶系统、实时响应系统和需要快速迭代的开发环境等,资源约束往往是最关键的考量因素之一。在这种条件下,若需满足快速微调的需求,采用“不思考”微调方式则显示出其独特优势。因此,在移动计算、医疗影像分析等必须在本地完成微调的应用场景中,当资源成本成为主要考量因素时,“不思考”微调方式展现出显著的实用价值。
值得注意的是,这一研究方向已获得业界的广泛关注。当前主流大模型厂商(如阿里云发布的通义千问 2.5 和字节跳动的豆包大模型 1.5)在模型设计中已开始整合思考模式的选择机制。
这种方法不仅解决了资源受限环境下的微调效率问题,还避免了因计算资源不足导致的性能下降,为边缘计算和移动端 AI 应用开辟了新的技术可能性。
日前,相关论文以《思考与不思考:基于规则的视觉强化微调中的显式思考研究》(Think or Not Think: A Study of Explicit Thinking in Rule-Based Visual Reinforcement Fine-Tuning)为题发表在预印本网站 arXiv[1]。李明是第一作者,张凯鹏担任通讯作者。

图丨相关论文(来源:arXiv)

“不思考”竟成微调最优路径?
在研究初期,研究人员提出将基础规则的强化学习(CLS-RL,Classification Reinforcement Learning)应用于分类任务,试图通过可验证的奖励机制来促进多模态大模型进行显式思考。
然而,实验过程中发现,以 DeepSeek-R1 为代表的大模型在强微调时会出现回答长度持续增加的现象,而 CLS-RL 在图像分类任务中的回答长度却呈现缩短趋势。
值得注意的是,训练完成后模型的思考过程对最终答案的贡献十分有限。这一现象促使研究人员提出了关键假设:在视觉感知任务(如图像分类)中,模型性能更多依赖于对图像本身的感知能力而非复杂的推理过程。
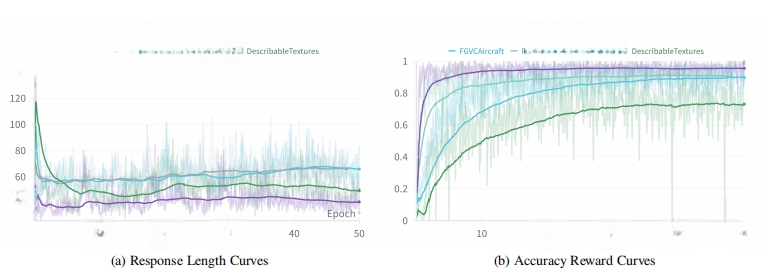
图丨不同微调阶段的响应长度和准确奖励的变化(来源:arXiv)
基于这一重要发现,研究团队创新性地调整了微调策略,让模型自发减少不必要的思考环节,直接输出答案而非采用“先思考再回答”的传统模式。
在少样本图像分类微调任务中,该框架的创新性主要体现在两个关键方面:
首先,研究团队创造性地将 DeepSeek-R1 的奖励机制引入分类任务,通过建立可验证的奖励体系,将多模态大模型的分类能力与传统强化学习相结合,使用分类类别名称作为奖励函数来替代传统的监督学习损失函数,这种设计使得模型能够直接优化整体回答策略而非局部 token 级别的优化。
其次,借鉴 DeepSeek-R1 的成功经验,采用结构化输出奖励机制,要求模型按照预设格式输出回答,在确保答案可验证性的同时鼓励模型进行多样化探索。
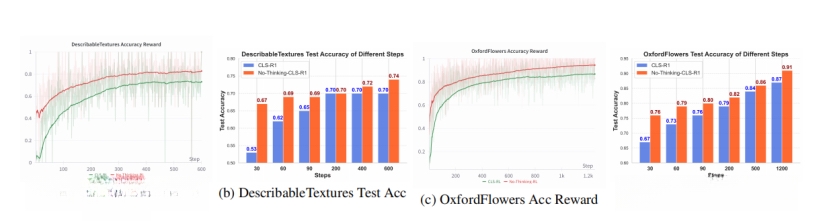
图丨CLS-RL 与不思考策略在步数上的准确度、奖励收敛速度及测试准确度的对比分析(来源:arXiv)
令人惊喜的是,这种简化策略不仅在特定领域任务上超越了 CLS-RL,在泛化能力方面也展现出显著优势,同时大幅提升了训练收敛速度,并大幅缩短了训练时间(减少约 94%)。
结果显示,在 11 个数据集中,“不思考”策略在 10 个数据集中的表现优于 CLS-RL,最终平均准确率比 CLS-RL 高出 3.14%。这表明,不包含思考过程的 RFT 能够有效提升模型在分类任务上的性能,优于包含思考过程的 RFT。
与传统 SFT 方法相比,CLS-RL 有效避免了模型对训练数据的机械记忆和由此引发的灾难性遗忘问题,而是引导模型学习任务的本质特征(如图像分类中的背景、光照等关键要素)。
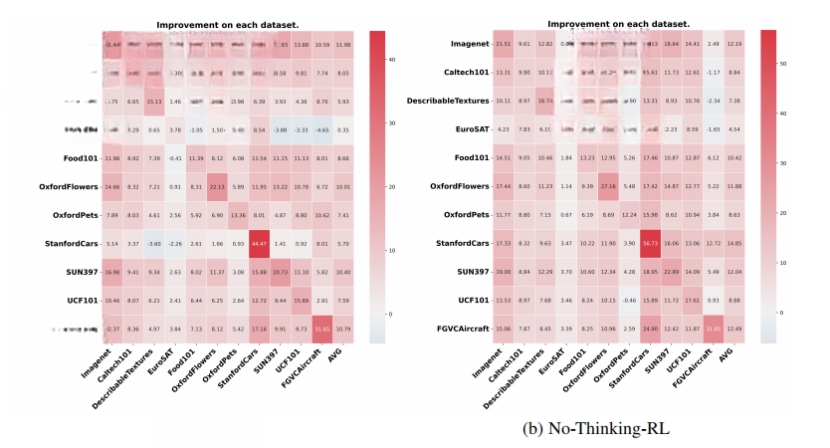
图丨CLS-RL 和无思考 RL 在不同数据集上的改进可视化,与零样本模型对比(来源:arXiv)
这种学习方式使得模型在未经微调的数据集上也能保持良好性能,研究团队将这种现象称为“免费午餐”(free-lunch)泛化效应。张凯鹏表示:“这种学习本质特征的能力显著降低了对特定领域数据的依赖性,不仅有效防止了知识遗忘,还实现了优异的跨领域迁移性能。”
为进一步探究显式思考对 RFT 过程的影响机制,他们提出了“先回答后思考”(Think-After-Answer)的创新方法,通过让模型先输出答案再生成思考过程的方式来减轻思考环节对决策的潜在干扰。
研究人员在数学推理、空间认知和谜题解答等多种任务上对“不思考”策略进行了系统验证,并对比分析了 2B 和 7B 两种规模模型的性能表现。
结果显示,在 2B 模型中,“不思考”的微调方式在所有任务(包括数学推理)上都优于基于思考的 RFT,而“先回答后思考”的表现居中。李明对此解释说道:“在处理复杂数学问题时,2B 模型由于参数量有限,难以生成高质量的推理链条。因此,即使在需要复杂推理的任务中,强制引入思考环节也无法带来性能提升。”
然而当模型规模扩大到 7B 时,情况发生了显著变化:更大规模的模型已经具备生成有效思维链的能力,在数学等复杂推理任务中,显式思考的微调方式展现出明显优势。
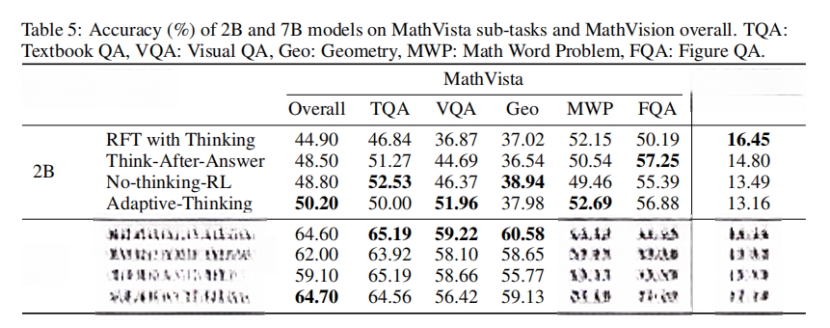
图丨2B 和 7B 模型在 MathVista 子任务及 MathVision 整体任务中的准确率(来源:arXiv)
RFT 的核心优势在于其能够显著降低数据标注和领域适配的成本。具体而言,若模型在自然图像分类任务上通过 RFT 完成微调,其学到的底层任务知识可能迁移至其他高标注成本领域(如医疗图像或遥感图像),从而避免重复收集标注数据的开销。
这种迁移能力的实现关键在于 RFT 是否真正教会模型理解任务本质,而非简单地记忆训练数据。如果模型能够通过 RFT 掌握通用的问题解决范式,而非局限于特定数据分布,那么这种能力有望扩展到更多标注资源稀缺的领域,从而实现跨领域性能提升与成本节约的平衡。
该研究不仅揭示了思考过程在不同任务中的差异化作用,建立了模型规模与思考策略有效性的关联规律,还为 RFT 在实际应用中的跨领域迁移潜力提供了理论支撑,对推动大模型的高效微调和实际部署具有重要的指导意义。

为构建通用大模型提供新思路
张凯鹏团队主要聚焦于多模态理解与生成、多模态评测等方向的研究。在评测体系构建方面,他们系统性地研究了包括单模态任务(如语言或代码相关任务)和多模态任务在内的各类评测任务,并先后构建了一系列涵盖通用能力和针对各类下游应用场景及专项能力的评测基准体系。
通过全面的评测实践,研究团队深刻认识到构建真正通用的多模态大模型面临巨大挑战,特别是在实现广泛场景覆盖能力方面存在的困难。

图丨李明(左)与张凯鹏(右)(来源:张凯鹏)
在团队早期的研究工作中,曾探索将多模态单一模型应用于各类视觉任务,包括多种分类任务及其他细分领域任务。研究发现,即便使用所有细分任务的数据进行联合训练,所得模型在多数任务上的表现仍显著落后于专家模型。
“通过采用自适应思考的强化学习微调方法,有望训练出在多个细分任务上均表现优异的通用大模型,这一发现为如何使单一模型适应多样化任务需求方面提供了重要启示。”张凯鹏说。
基于这一认识,该团队当前正重点研究如何根据具体任务属性和模型能力水平,自适应地确定最优的训练策略和思考模式。这一研究方向为 AI 模型的训练优化开辟了新思路。
以自动驾驶为例,对于简单的感知类任务(如障碍物检测),采用“不思考”的直接响应模式更为高效;而对于复杂的决策任务(如路径规划),则需要模型进行深度推理和规划。
在现有自动驾驶系统中,通常采用多个专家模型并行处理不同任务。若将所有任务数据输入单一模型,不仅难以实现任务间的协同促进,反而可能引发任务冲突。因此,自适应思考机制(Adaptive-Thinking)的引入,有望减少任务冲突,增强正向迁移,使单一模型能够胜任更多任务,这对工业场景的实际部署具有重要意义。
与此同时,他们还在积极探索多任务混合训练的新范式,旨在使混合模型在保持通用性的同时,达到甚至超越专家模型的性能水平,这或将为多模态大模型的发展开辟新的技术路径。
此外,本次研究的发现还促使该团队深入思考 AI 系统与人类认知和思考方式的差异,特别是在资源分配和任务处理机制方面的不同特性。这些基础性的探索不仅有助于揭示 AI 与人类智能的本质差异,也可能为未来大模型框架的创新提供重要参考。
1.https://arxiv.org/pdf/2503.16188
2.https://github.com/minglllli/CLS-RL/tree/main
排版:刘雅坤、何晨龙
