热点推荐
热门图文

导语
在人工智能领域,大语言模型(LLMs,如 Claude 3.5 Haiku )已展现出强大的语言处理能力,但其内部运作机制仍如“黑箱”般难以理解。为揭示这些模型的内部结构,Anthropic团队在其研究论文《On the Biology of a Large Language Model》中,引入了一种名为“归因图”(Attribution Graphs)的新方法。该方法类似于神经科学中的连接组学,旨在追踪模型从输入到输出的中间计算步骤,从而生成关于模型机制的假设,并通过后续的扰动实验进行验证和完善。通过归因图,研究人员能够部分揭示模型内部的特征及其相互作用方式,进而理解模型在处理多步推理、诗歌创作、医学诊断等任务时的内部机制,这项研究不仅为大型语言模型的可解释性提供了新的视角,也为未来的人工智能安全性和可靠性研究奠定了基础。
集智俱乐部翻译了此文章,由于篇幅过长,我们将分为上、中、下三期推送。本文为系列文章的第一部分,主要介绍了方法的原理与局限,并结合多步推理、诗歌生成与多语言处理等任务,展示了模型内部结构的复杂性与功能分化。在阅读时,您可以思考以下问题:
1. 大语言模型在推理时会走捷径吗?
2. 大语言模型作诗是即兴还是规划的?
3. 大语言模型有自己独立的原生语言吗?
前往集智斑图获得更好阅读体验:
关键词:大语言模型、Claude 3.5 Haiku、归因图、回路结构、多步推理、诗歌创作、多语言回路
Jack Lindsey, Wes Gurnee等丨作者
赵思怡|译者
读书会推荐
集智俱乐部也联合上海交通大学副教授张拳石、阿里云大模型可解释性团队负责人沈旭、彩云科技首席科学家肖达、北京师范大学硕士生杨明哲和浙江大学博士生姚云志共同发起,从Transformer circuits、等效交互、复杂科学与系统工程的视角一起探讨如何打开AI黑箱,欢迎你加入。
文章题目:On the Biology of a Large Language Model
文章地址:https://transformer-circuits.pub/2025/attribution-graphs/biology.html
文章作者:Jack Lindsey(†),Wes Gurnee(*),Emmanuel Ameisen(*),Brian Chen(*),Adam Pearce(*),Nicholas L. Turner(*),Craig Citro(*),David Abrahams,Shan Carter,Basil Hosmer,Jonathan Marcus,Michael Sklar,Adly Templeton,Trenton Bricken,Callum McDougall(◊),Hoagy Cunningham,Thomas Henighan,Adam Jermyn,Andy Jones,Andrew Persic,Zhenyi Qi,T. Ben Thompson,Sam Zimmerman,Kelley Rivoire,Thomas Conerly,Chris Olah,Joshua Batson(*‡)
† Lead Contributor; * Core Contributor;‡ Correspondence to joshb@anthropic.com; ◊ Work performed while at Anthropic;
目录
1. 背景
2. 方法论概览与局限
3. 多步推理:在模型内部进行复杂的推理过程。
4. 诗歌创作中的规划:生成诗歌时提前规划押韵词。
5. 多语言回路:混合的语言特定回路与抽象的语言无关回路结构。
6. 加法运算:相同的加法回路如何在不同上下文中泛化。
7. 医学诊断:根据报告的症状识别候选诊断,并据此提出后续问题,以验证诊断。
8. 实体识别与幻觉:在识别实体时可能出现幻觉现象。
9. 拒绝响应:在面对敏感或不当请求时的拒绝机制。
10. 越狱行为分析:在特定提示词下可能违反预期行为的情况。
11. 思维链忠实性:评估模型在多步推理中的一致性和可靠性。
12. 误导性目标的识别:在训练中可能学习到的与预期不一致的目标。
13. 常见回路组件和结构:总结模型中普遍存在的回路模式和结构。
14. 局限性与开放讨论
15. 总结与未来展望
1. 背景
随着大语言模型(LLMs)能力的飞速提升,其“黑箱”性质带来的不透明性问题愈加突出。尽管这些模型能执行复杂任务,其内部计算机制却仍难以理解。这种局限性阻碍了我们对模型行为的信任和控制,尤其是在它们被广泛应用于现实世界场景的背景下。因此,研究者们希望通过“逆向工程”的方式揭示模型的内部结构和计算原理,从而提升其可解释性与可控性。这一研究方向类似于生物学家理解复杂生命体的努力(进化基本原理简单,但生物学机制复杂):语言模型虽然源自简单的训练算法,但其产生的内部机制就像生物系统一样复杂,需要通过新的“显微镜”——即模型分析工具——才能洞察其中奥秘[1,2,3,4,5]。本文正是在这一背景下,通过提出和应用“归因图”方法,对模型内部机制展开系统探索。
本文研究结果显示,模型展现出多层次的复杂策略运用能力。以 Claude 3.5 Haiku 为例,其常常进行多重内部推理步骤,这些计算主要发生在神经网络的前向传播阶段,而非通过显性的思维链输出呈现。该模型显示出前瞻规划的迹象,能在最终输出前预先推演多种可能性方案,同时展现出逆向推导能力,可基于目标状态反向构建回答框架。研究还观察到基础的元认知机制,使模型能动态评估自身知识边界。更广泛地说,模型的内部计算高度抽象,并具有跨场景泛化应用的特性[5,6,7,8]。我们的方法有时还能审核模型的内部推理步骤,即便最终响应表现正常,仍可识别潜在的风险轨迹。
2. 方法论介绍
2.1 归因图构建
研究分析的模型基于Transformer架构。这类语言模型接收token序列输入(如单词、词片段、特殊字符),逐个生成新token。模型包含两大核心组件:其一是多层感知机层(MLP),通过神经元集群处理每个token位置的信息;其二是注意力层,负责在不同token位置间传递信息。
模型难以解释的一个原因在于神经元普遍具有多重语义功能,即单个神经元会执行看似无关的多种操作,这种现象源于“叠加”效应——模型表征的概念数量超过神经元总量,因此无法为每个概念分配专属神经元。为解决这个问题,我们构建了替代模型,该模型基于跨层转码器(CLT,Cross-Layer Transcoder)架构,经过定向训练,可将原模型的MLP神经元替换为特征,即稀疏活动的“替代神经元”,这些神经元通常代表可解释的概念。本研究所用CLT架构,各层总计包含三千万个特征,近似复现原模型的激活状态。
在原始的Transformer模型中,神经元处理token(如Token1、Token2、Token3等),并通过和注意力层进行信息传递,最终输出结果。 我们研究的基础模型采用基于Transformer架构的大语言模型。原模型的神经元被替换为特征。特征数量通常远多于神经元数量。这些特征激活较为稀疏,常对应可解释的语义概念(如图1所示)。
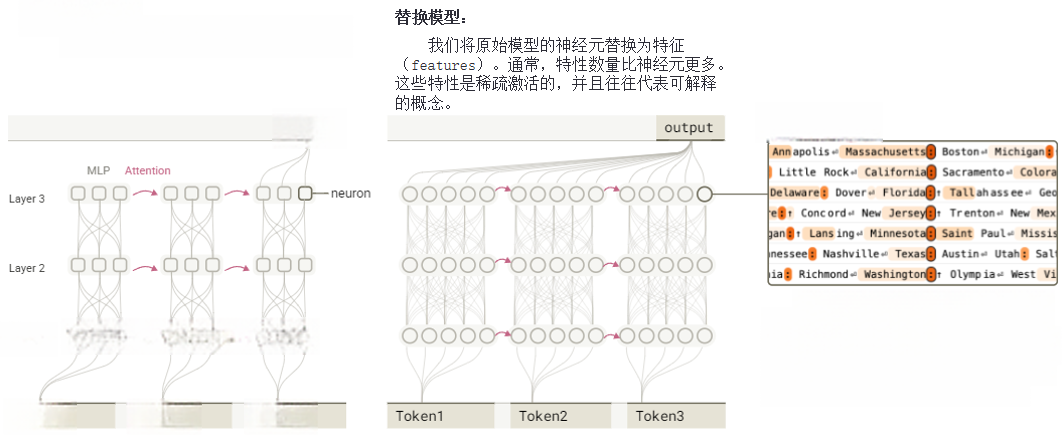
图1 替换模型通过跨层转码器的稀疏激活特征替代原模型神经元而构建
特征通常代表从低级(如特定单词或短语)到高级(如情感、计划和推理步骤)的人类可解释概念。通过分析特征在不同文本样本中的激活情况,可为每个特征标注人类可理解的标签。需特别说明,本文所有文本样本均选自开源数据集。
值得注意的是,替换模型无法完全复现原模型的激活状态。对任意输入提示词,两者间存在差异。我们引入误差节点弥补差异,这些节点表征模型间差距。与特征不同,误差节点难以解释,但引入它们可更精确评估解释的完整度。此外,我们的替代模型并不试图替换原始模型的注意力层,处理输入提示词时,直接使用原模型的注意力模式,并将其作为固定组件。
我们将这种整合误差节点、继承原模型注意力机制的模型命名为局部替换模型。其“局部性”体现在:不同提示词会生成不同的误差节点和注意力模式,但它仍尽可能多地使用(某种程度上)可解释的特征来表示原始模型的计算(如图2所示)。
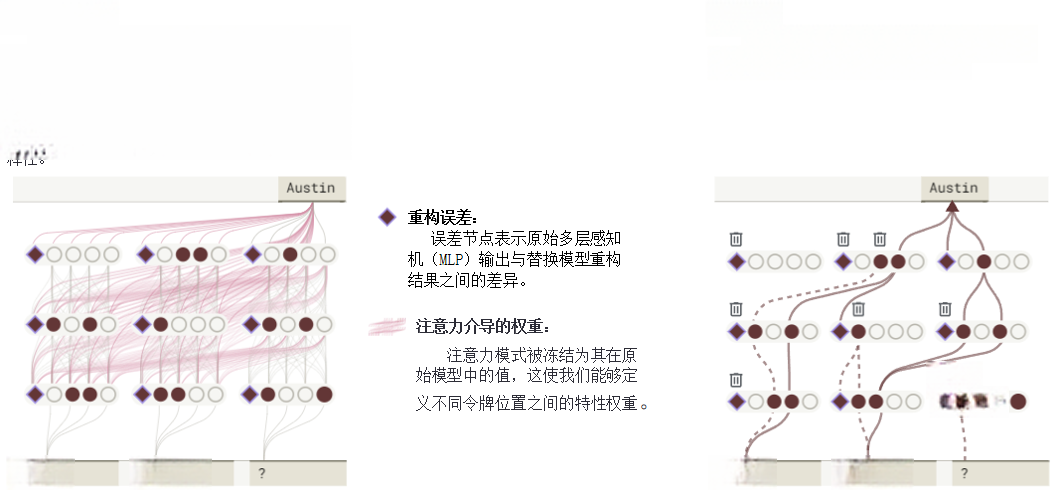
图2 局部替代模型通过向替代模型添加误差项和固定的注意力模式,以精确重现原始模型在特定提示词上的行为
通过分析局部替换模型中的特征交互,可追踪其生成响应时的中间步骤。具体方法是构建归因图:节点代表特征,边表示因果联系,以此图形化呈现模型处理输入时的计算路径。由于归因图可能过于复杂,需要修剪对输出影响较小的节点与边,仅保留最关键的核心部分。当我们手头有一个经过剪枝的归因图时,经常会发现一些意义相关节点组成的特征组。通过手动将特征组中的节点归类为超节点,即可获得简化后的归因图,即模型执行计算过程的简化描述(如图3所示)。
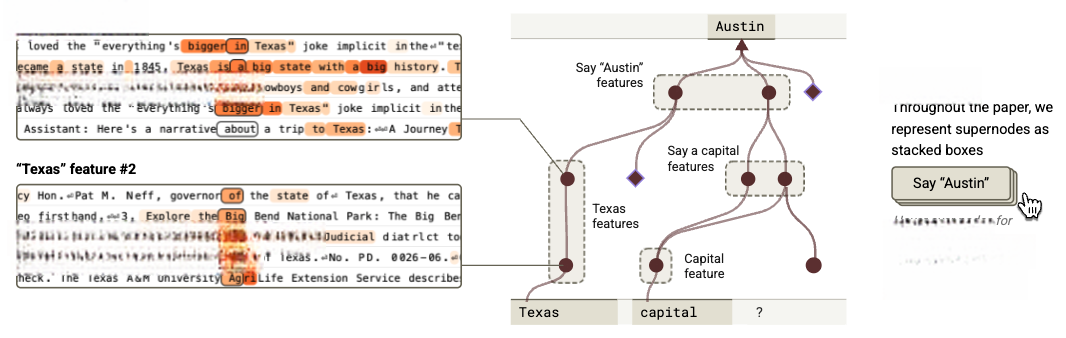
图3 将剪枝后的归因图中相关节点合并为超节点的过程示意(文中用堆叠按钮表示超节点)
2.2 归因图解释效力的干预试验
基于上述步骤得到的模型计算的归因图如图4(左)所示。由于归因图基于替代模型构建,我们无法通过归因图确定性地得出关于底层模型(即 Claude 3.5 Haiku)的结论。因此,归因图仅提供关于底层模型中可能存在的假设。这些假设可能存在局限,具体讨论请见后文局限性一章。为验证机制真实性,我们在原模型进行干预实验,例如抑制某些特征群组并观察其对其他特征及输出的影响(路径上的百分比表示原始激活保留量)。若结果符合归因图预测,我们就可以更有信心地认为该图捕捉到了模型内部的真实(尽管可能是不完整的)机制。需注意:所有特征标注与“超节点”归类均在扰动测量前完成。

图4 (左)简化后的归因图,即模型执行计算过程的简化描述(这是一个交互式图表);图4(右):为检验归因图的解释效力,在原模型实施干预实验(注:图示数据仅为流程演示,非真实实验结果)
交互式图表可点击链接进入网页,将鼠标悬停在超节点上,可查看特征组成的可视化效果: https://transformer-circuits.pub/2025/attribution-graphs/biology.html
干预实验结果的解读具有复杂性,其对归因图机制的验证程度详见[96]。使用跨层转译器特征进行干预时,需要选择“干预层”,并在该层之前进行扰动。本文采用“约束修补”技术:将干预层前的激活值固定为扰动状态,避免间接效应提前显现。因此,干预层之前的特征受到扰动的影响必定与归因图预测的直接效应一致。而干预层之后特征受到扰动可能出现两种偏差:一是归因图预测效应可能被遗漏机制覆盖;二是预测的间接效应(多级交互)可能不存在(称为“机制失真”)。因此,干预实验的验证效果因特征层级而异。总体而言,我们认为干预对模型实际输出的影响是最为重要的验证来源,因为模型输出易于解释,并且这种干预方式确保了对特定特征的调整能够在不干扰其他计算的情况下,精确地评估该特征对模型输出的影响。
在每个案例研究图示旁,都提供了交互式的归因图界面。该界面完整呈现了研究团队探索模型内部机制时采用的详细视图。您可以通过该界面“追踪”关键路径,同时标注关键特征、特征群组和子回路。需要注意的是,界面操作较为复杂,需要一些时间才能熟练使用。本文中的所有关键结果都以简化形式进行了描述和可视化展示,因此不需要使用此界面即可理解内容!但若读者希望深入探索Claude 3.5 Haiku的运作机制,我们仍强烈建议尝试操作。部分特征附有简略标签以便快速识别,但需注意这些标注仅为示意性质,详细信息请参考对应的特征可视化图示。具体操作指南请查阅方法论文的专项章节。
2.3 方法论总结
就像任何显微镜都有其观察的局限性一样,我们的工具有观测盲区。尽管虽然难以精确量化,但发现归因图能够对四分之一的提示词提供有效解析。文中精选案例虽属成功解析对象,但需注意:即使在这些案例中,所揭示机制也仅是模型运作的极小部分。我们的方法通过使用一个更可解释的“替代模型”间接研究原模型,然而这种替代模型对原模型的描述,既不完整也不完美。
此外,为保持表达清晰,我们常对研究发现进行高度浓缩,并采用主观筛选的简化处理。这种处理方式会进一步丢失信息。为更真实反映发现的复杂性,我们提供“归因图交互界面”供读者探索。但必须指出:即使这些相当复杂的图表,仍是对底层模型的简化呈现。
本文聚焦于精选案例研究,旨在揭示特定模型的关键机制。这些案例作为存在证明,即具体证据,表明特定机制在特定情境中确实运行。我们虽然推测类似的机制可能更广泛存在,但无法保证其普遍性,我们会在后文开放问题中对此详细讨论,方便后续研究的开展。需注意的是:所选案例受工具局限性影响,存在样本偏差。但我们在识别出感兴趣的案例研究后,会通过后续验证实验对我们的发现进行压力测试。若需系统评估方法详见[96]。
然而我们认为:定性研究才是评估方法的最佳标准,正如显微镜的价值最终由其促成的科学发现来决定。这类工作对推进AI可解释性至关重要,这是一个仍在寻找合适抽象概念的前范式领域——如同生物学依赖描述性研究实现突破。我们尤其感到振奋的是,充分挖掘现有方法所能提供的最大洞见,不仅让我们更清晰地看到了这些方法的具体局限性,也为该领域未来的研究指明了方向。值得关注的是:深入挖掘现有方法后,其特定局限更清晰显现,这可能会为该领域的未来的研究提供指引。
3. 入门案例:多步推理
我们的方法旨在揭示模型在生成响应过程中所使用的中间步骤。在本节中,我们以一个简单的多步推理为例,并尝试识别每个步骤。在此过程中,我们将突出显示在后续案例研究中会反复出现的关键概念。
让我们分析这个提示词:“Fact: the capital of the state containing Dallas is”当Claude 3.5 Haiku成功输出“Austin(该州首府)”时,其推理过程需要两个步骤——首先推断Dallas所在州是Texas,接着确认该州首府为Austin。Claude 是否真的在内部执行了这两个步骤?还是它使用了某种“捷径”(例如,也许它在训练数据中见过类似的句子并简单记住了答案)?已有研究[13,14,15]证实存在真实的多步推理(不同情境下程度各异)。在本节中,我们将提供证据表明,在此案例中,模型内部既存在真实的两步推理,也保留着“捷径”机制。
正如第2章方法论的概述所描述的,我们通过计算该提示词的归因图来解决这个问题,归因图可展示模型生成答案时使用的特征及其互动关系。首先解析出特征的可视化图示来理解其含义,再将特征归类形成超节点。例如:
-
几个与“capital”这个词或概念相关的特征,例如四个对“capital”这个单词激活最强的特征。更有趣的是,我们还发现了一些以更通用方式表示“capital”概念的特征。例如:它不仅在单词“capital”上激活,还会在关于各州首府的问题中以及中文问题“广东省的省会是?”中激活,特别是对“省会”一词有反应。另一个例子则展示了模型的多语言特征,它在包括“başkenti”、“राजधानी”、“ibu kota”和“Hauptftadt”在内的多种表示“capital”的短语上激活最强(德语部分内容的混乱可能是由于转录错误)。虽然这些特征各自表达的概念略有不同,但在本提示词的上下文中,它们的功能似乎是代表“capital”这一概念。因此,我们将它们(以及其他一些相关特征)归类到同一个超节点中。
-
一些输出特征,这类特征能持续推动模型输出特定token,即使其激活的词语并没有明显规律。在特征可视化界面中,“Top Outputs”部分会显示受该特征直接影响最强的输出标记。例如某个特征对Texas州中部多地标都有响应,但在当前提示词中最关键的作用是大幅提升“Austin”标记的输出概率,因此我们将其归入“say Austin”超级节点。需注意,“Top Outputs”信息并非总是有效——如浅层特征主要通过间接路径影响输出,其直接影响的顶部标记作用有限。判定某特征为输出特征时,需综合评估其直接影响最大的输出项、激活语境以及在归因图中的功能。
-
多个促进首都名称输出的广义特征。这些特征采用“混合信号机制”进行识别标注。例如,某特征会增强美国各州首府的输出倾向,另一特征更侧重提升各国首都的概率(而非美国州首府),但它在包含美国州及其首府列表的情况下激活最强。我们还注意到另一个特征,其最强的直接输出是一组看似不相关的标记,但该特征经常在提到国家首都(如Paris, Warsaw, Canberra)之前激活,这些特征都被整合至“say Austin”超级节点。
-
多个特征与“Texas”的多种情境相关联,这些特征并不指向具体城市(尤其不涉及“Dallas”或“Austin”)。尽管每个特征都代表了不同的、具体的与“Texas”相关的概念,但在当前提示词中共同体现了“Texas”整体概念。因此将其合并为“Texas”超级节点。
在形成这些超级节点后,可以在归因图界面中看到:“capital”节点会提升“say a capital”节点,该节点进而推动“say Austin”节点。我们用棕色箭头连接这些节点,如下方示意图所示:
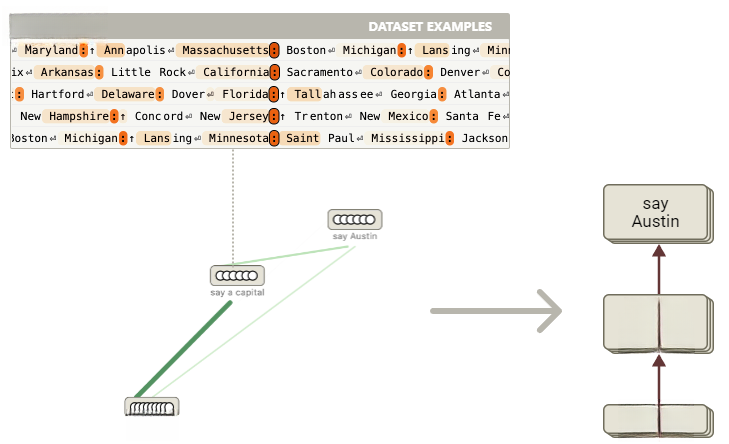
图5 通过特征可视化分析标注后,手动将相同提示词要素归为超节点。归因图聚合了超级节点间的关联,图中棕色箭头表示强关联节点
在标记更多特征并形成更多超节点后,可以看出归因图中存在多条关键路径,具体如下:
-
“Dallas”特征(以及部分来自州特征的贡献)激活了一组与“Texas”相关概念的特征。
-
与此同时,由“capital”一词激活的特征触发了另一组输出特征集群,使模型倾向于说出一个首府的名称(上述内容中可以看到这样的特征示例)。
-
“Texas”特征和“say a capital”特征共同提升了模型说出“Austin”的概率。它们通过两条路径实现这一点:
-
-
直接影响“Austin”输出;
-
间接激活“Austin output”特征群。
-
-
此外,还存在一条从“Dallas”直接到“say Austin”的“捷径”边。
该图表明,替代模型确实执行多步推理——即生成“Austin”的决策依赖多步计算链(Dallas→Texas,Texas+capital→Austin)。需注意此图为高度简化版本,建议读者操作交互式可视化工具,查看完整图表以理解底层复杂性。
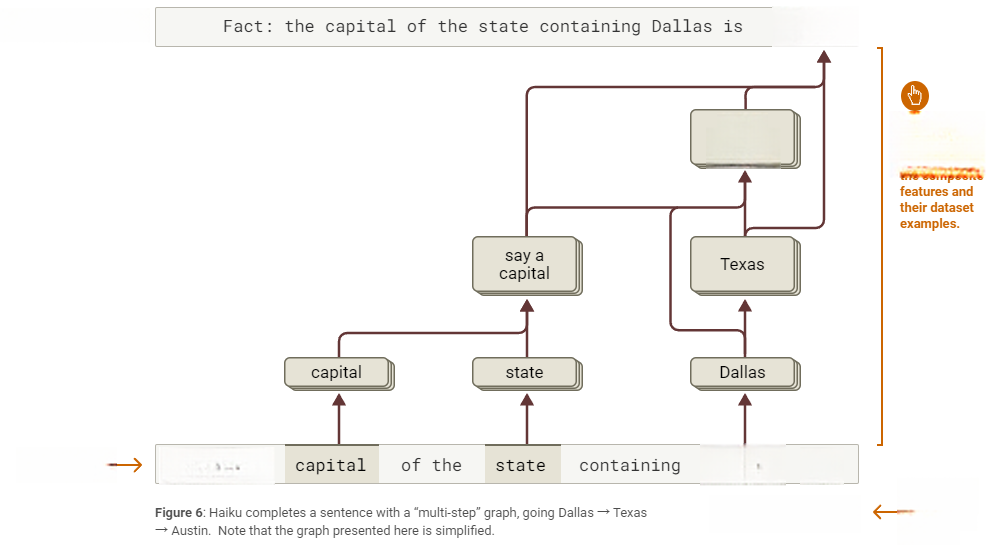
图6:Haiku通过Dallas→Texas→Austin实现多步推理(交互式图表)
3.1 抑制实验验证
上述图表展示了可解释替代模型的运作机制。为验证该机制能真实反映原模型,我们对特征群进行干预实验:将各特征值限定为原始值的负倍数,同时观测其对其他特征群激活程度及模型输出的影响。
干预强度选择方法详见:Circuit Tracing: Revealing Computational Graphs in Language Models(https://transformer-circuits.pub/2025/attribution-graphs/methods.html)
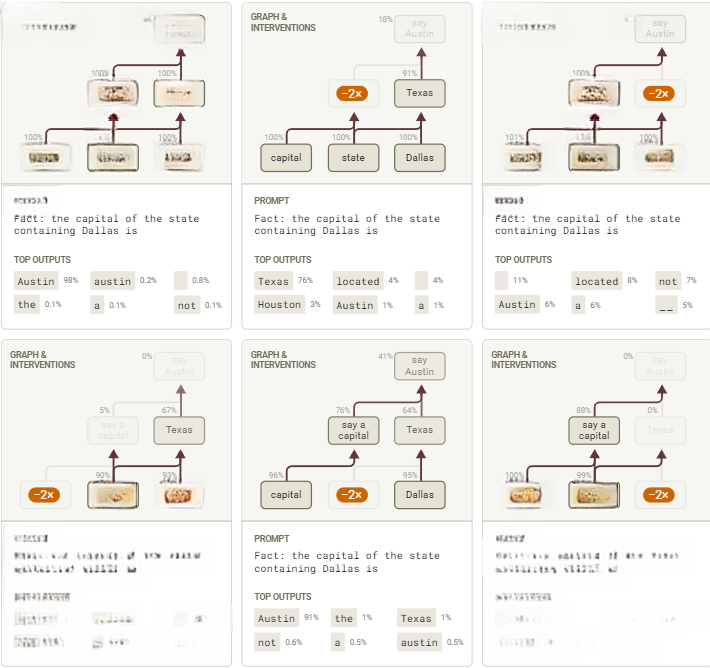
图7 达拉斯首府提示词的干预测试,节点激活值均以基线激活为参照基准
上述总结图证实了图表预测的主要效果。当抑制 “Dallas”特征时,“Texas”特征激活明显下降(并影响其下游特征,如 “Austin output”特征),但 “capital output”特征基本不受影响。类似地,抑制 “capital”特征 时,“capital output”特征激活减弱(并影响下游的 “Austin output”特征),而 “Texas”特征则保持稳定。
抑制特征对模型预测的影响在语义上合乎逻辑。例如:抑制 “Dallas”特征簇 时,模型会输出其他州首府;抑制 “say a capital”特征簇时,则会生成非首府答案。
3.2 交换替代特征
若模型的回答确实通过“Texas”中间步骤产生,我们可通过替换模型的“Texas”特征,使其输出不同州的首府。为识别其他州对应的特征,我们改用包含“Oakland”的提示词:“Fact:the capital of the state containing is(Oakland所在州的首府是?)”。重复前述分析步骤,获得如下摘要图:
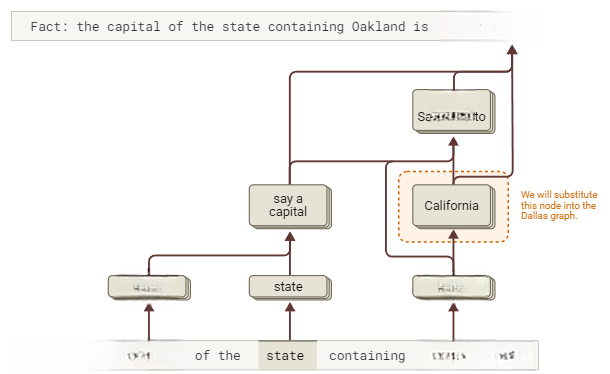
图8:Haiku使用“多步骤”图生成回答,路径遵循Oakland→California→Sacramento(交互式图表)。
该图表与原图形成类比:“Oakland”、 替代 “Dallas”,“California” 替代“Texas”,“say Sacramento” 替代 “say Austin”。
现在回到初始提示词,通过抑制 “Texas特征簇”的激活,同时启动从“Oakland”提示词提取的 “California”特征实现“Texas”到“California”的替换。经此调整后,模型输出变为“Sacramento”(California首府)。
同理,
-
使用涉及“Savannah”所在州的类比提示词时,会激活 “Georgia”特征。若将其替换为 “Texas”特征,模型将输出“Atlanta”(该省首府)。
-
采用涉及“Vancouver”所在省的类比提示词时,会激活 “British Columbia”特征。将其替换为 “Texas”特征后,模型转而输出“Victoria”(该省首府)。
-
当使用涉及“Shanghai”所属国的类比提示词时,会激活 “China”特征。替换为 “Texas”特征后,模型即输出“Beijing”(中国首都)。
-
在涉及“Thessaloniki”的类比提示词下,会激活 “Byzantine Empire”特征。将其替换为 “Texas”特征后,模型则输出“Constantinople”(该国古都)。
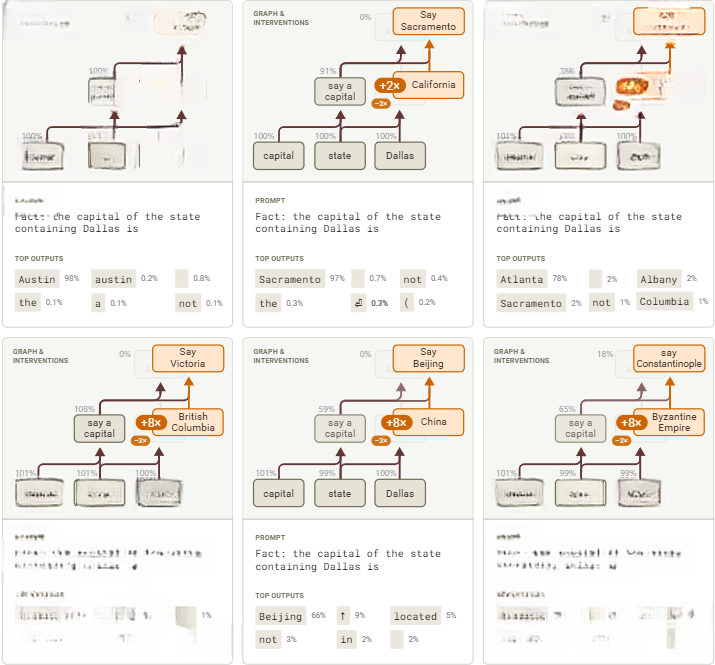
图9:通过干预措施将Dallas首府提示词中的Texas,替换为其他州、省及国家。节点激活程度以基线激活为参照基准
值得注意的是,在某些情况下,改变模型输出所需的特征注入幅度明显更大(见Top Outputs)。有趣的是,这些情况对应于被注入的特征并不表示美国的一个州,这表明此类特征可能更难融入原提示词激活的回路机制。
4. 诗歌中的规划
Claude 3.5 Haiku 如何创作押韵诗?写诗需要同时满足两个条件:既要保证诗句押韵,又要保证语义通顺。关于模型的实现方式,存在两种可能性:
-
完全即兴——模型先随意撰写诗句开头,不考虑押韵需求。直到行末时,才选择既符合语义,又能押韵的词语。
-
规划策略——采用更复杂的方法:模型在每行起始时,结合押韵规则和前文内容,提前选定行尾词。然后用这个“规划词”反向构思整行诗句,使尾词自然融入。
语言模型基于逐词预测训练而成,按此逻辑,本应偏向即兴策略。然而我们发现了支持存在规划机制的有力证据。具体表现为:模型在撰写诗句前,常会先激活候选尾词的特征,并利用这些特征决定如何组成该行。在我们分析的诗歌中,约半数存在这种规划词特征,未能观测到的情况,可能由于CLT未捕捉相关特征,也可能说明模型并非每次都进行规划。
在生成押韵对句时,Haiku似乎会在第一行结束时规划下一行的候选结尾。例如图10:
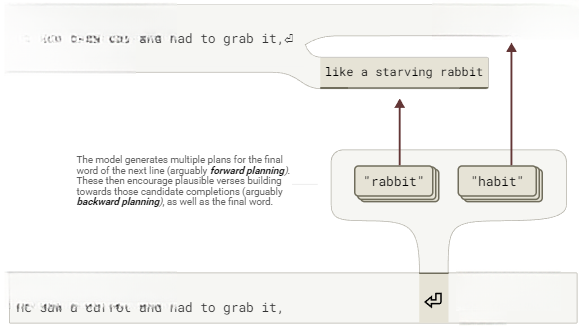
图10:Claude 3.5 Haiku创作押韵对句时,首句末尾便开始规划下句可能结尾。需要说明:此示意图是对本节研究结论的宏观呈现(交互式图表)。
模型会为下一行尾词生成多个候选方案,这些方案既推动诗句构建方向,也影响最终用词选择。主要涉及两种规划方式:前向规划、后向规划。
此例子增加了语言模型和其他序列模型中存在规划的证据库(例如游戏领域研究[16,17,18,19,20,21]),并且在几个方面尤为引人注目:
-
从机制层面解释规划词如何被选择并用于后续流程。
-
发现前向规划与后向规划并存(虽为基础形式)的证据。首先,模型会根据诗意与押韵要求选定候选词,再从目标词倒推构建自然收尾的语句。
-
观察到模型能同时“记住”多个候选规划词。
-
通过修改模型规划词,可看到后续诗句结构的相应调整。
-
该机制通过无监督的、自下而上研究方法发现。
-
规划词所用特征与常规词语特征一致,表明模型“思考”规划词时,其表征方式与普通词语处理相同
我们研究Claude如何完成押韵对句的提示词。模型逐步生成最可能词元的输出如下(粗体部分):
首先,聚焦第二行末尾的“rabbit”,并尝试识别出其生成回路。我们原以为会发现即兴创作过程——押韵特征与语义特征相互叠加,共同推动“rabbit”的选择,结果却发现:关键机制组件竟定位在第二行起始前的换行符处:
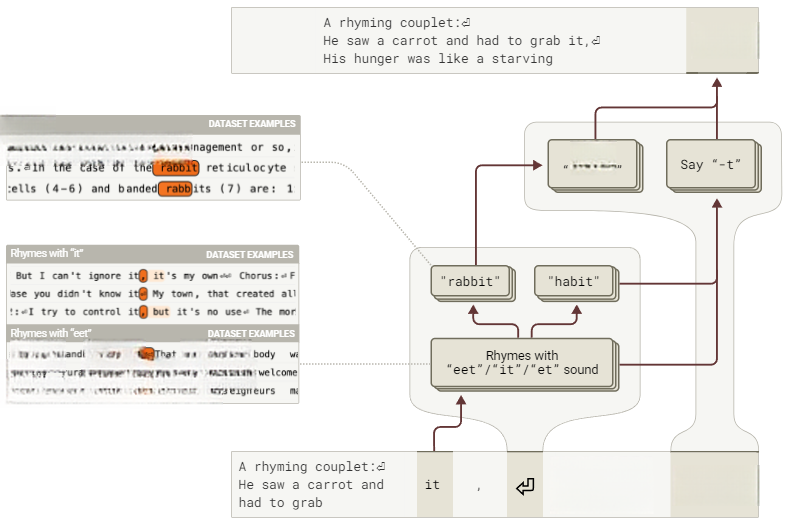
图11:Haiku最终选定“rabbit”,关键在于该词在上句结束时已被规划为潜在收尾词(交互式图表)。
上述归因图通过从“rabbit”输出节点回溯计算得出,显示了在第二行开始前的新行token上活跃的一组重要特征。在“it”token上活跃的特征激活了与“eet/it/et”押韵的特征,这些押韵特征自身又激活了如“rabbit”、“habit”等候选补全的特征!这些候选补全特征接着在最后一个标记上有正向边指向说“rabbit”的特征,最终促进了相应输出标记的出现。这与模型提前规划潜在补全是一致的。完整的回路展示了多种特征群,这些特征群促进了潜在补全的早期音素,例如包含与“grab”中的“ab”声音匹配的词的声音特征。
为了测试这一假设,我们在新行规划点进行了多种干预措施,并观察其如何影响最后一个token的概率。我们抑制了计划词和押韵模式的特征,并注入了不同的押韵模式和计划词。
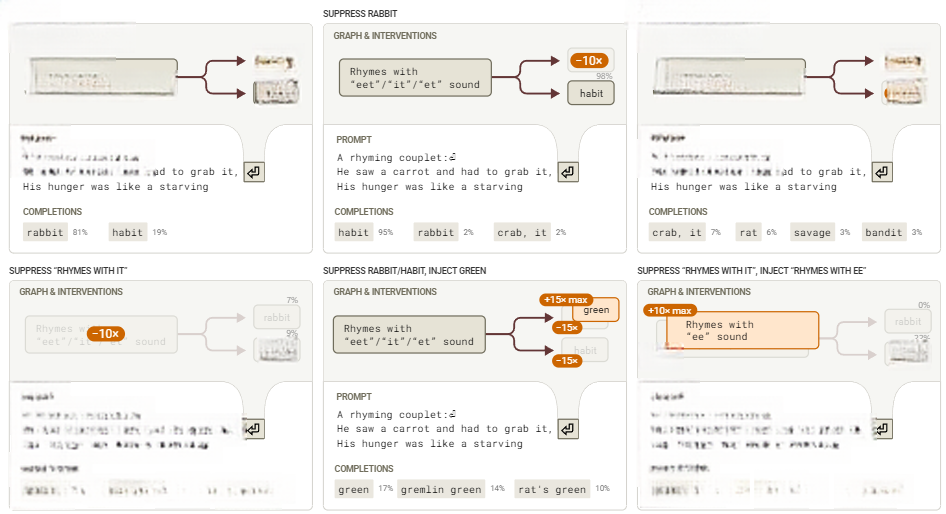
图12:干预措施测试了我们对诗歌示例中最后一个标记补全的理解。节点激活度以基线最大值为准。结果证实了我们的假设,即这些规划特征对最后一个标记的概率有强烈影响
4.2 规划特征仅作用于规划位点
回路分析表明,规划发生在新行token处。实际上,这些特征仅在规划token上活跃。下面,我们展示了通过改变我们在哪个token上进行引导来预测不同最终标记的概率。在每个索引处,我们对“rabbit”和“habit”特征进行负向引导,而对“green”特征进行正向引导。“green”特征是我们从另一首诗中找到的一个等效规划特征,它在多种情境下激活,包括单词“green”的各种拼写错误。我们观察到,只有在新行规划token处进行引导干预才会有效果!
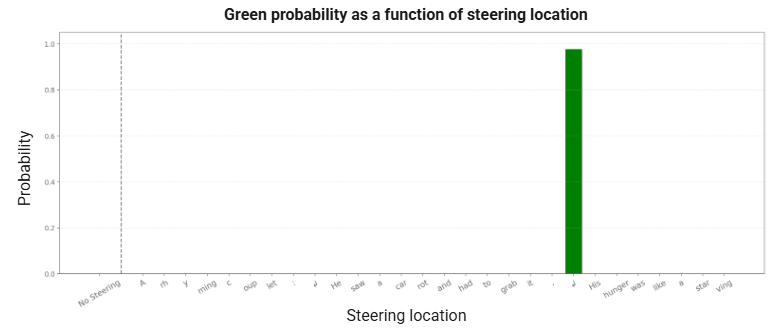
图13:转向位置对应的“green”概率。只有在规划位置进行转向才是成功的(换行符处)
4.3 规划词如何影响中间词
规划回路仅控制收尾词选择,还是它也会导致模型在生成中间词时“朝着目标写作”?为此,我们计算了中间词“like”的归因图。
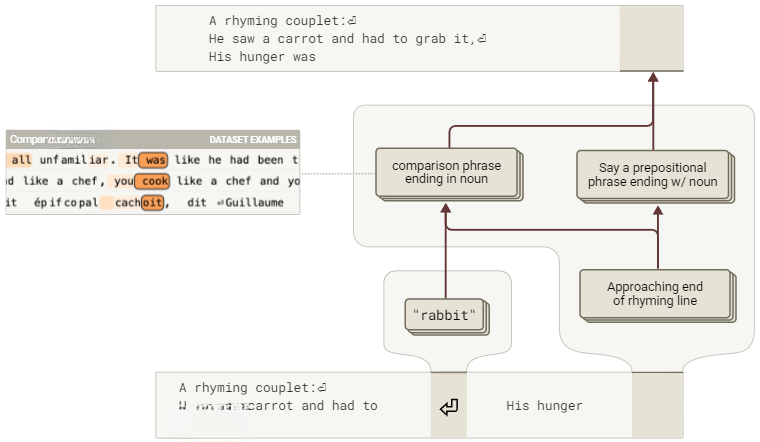
图14:从“rabbit”这一目标反向推导,Haiku增加了中间词“like”的概率,从而“朝着目标写作”。这表明规划回路不仅决定了最终词的选择,还在生成过程中对中间词产生了显著影响,使整个句子自然地导向目标词(交互式图表)。
相同的“rabbit”规划特征在图中处于活跃状态,这些特征推动了一组“比较特征”,这些特征在诸如“like a”之类的文本之前被激活。模型从在新行标记处激活的计划目标(“rabbit”)开始,反向推理,创建一个合理的过渡以自然地引出该目标。
我们再次通过干预实验验证了这一点。我们发现,抑制“rabbit”特征会改变过渡内容,使其与另一个计划词“habit”相匹配。
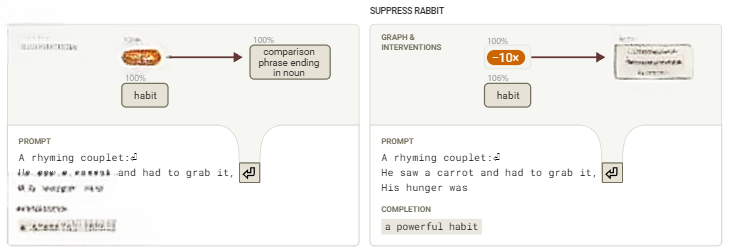
图15:抑制“rabbit”特征对行补全的影响,将其从“like a starving rabbit”改为“a powerful habit”
4.4 规划词决定句式结构
规划特征是否会影响整体句式结构?我们通过进一步的引导实验来测试这一点:保持原有干预设置,但重新采样整行最后一个词。实验结果表明,对规划特征的干预会改变句式结构,以生成一个与干预相匹配的最终词语。

图16:验证我们对诗歌示例中整行最终补全机制理解的干预实验。节点激活程度是相对于最大基线激活水平进行衡量的。
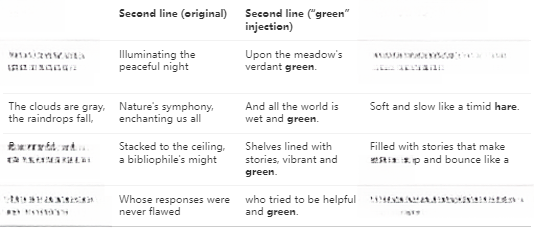
除此之外我们还在随机选取的25首诗中注入了两个计划词特征(“rabbit”和“green”),并发现模型在70%的情况下会在行末使用注入的计划词。我们在下方展示了一些成功案例的样本。
5. 多语言回路
现代神经网络具有高度抽象表征,常将跨语言概念统一(如多语言神经元特征[22,23,24]、多语言表征研究[25,26,27,28],其他[29,30])。然而,我们对于这些特征如何在更大的回路中协同工作、从而产生模型的可观测行为的理解仍然十分有限。
本节观察 Claude 3.5 Haiku如何补全三种语言的同义提示词:
-
英语: “The opposite of 'small' is”→ “big”
-
法语: “Le contraire de 'petit' est” → “grand”
-
中文: “‘小’的反义词是” → “大”
我们发现这三个提示词由高度相似的回路驱动。这些回路既包含共享的多语言组件,也具备对应的语言特定组件,这种结构可视为语言不变回路与语言等变回路的组合[31]。核心机制可概括如下:
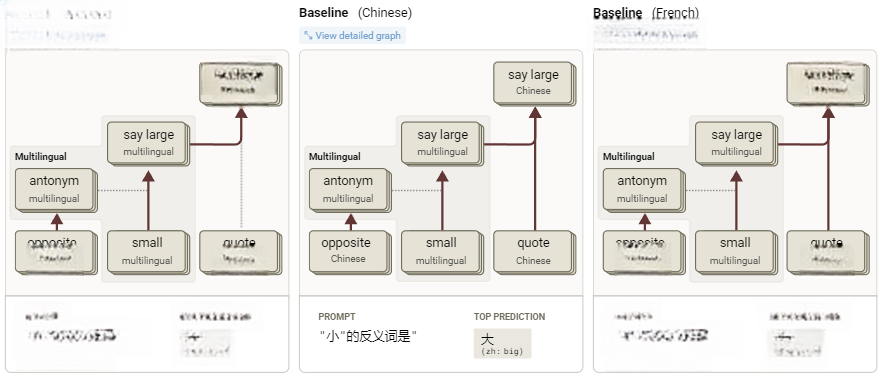
图17:询问Haiku在不同语言中“small”的反义词是什么时,计算过程的关键部分显示出重叠的多语言通路(交互式图表)。
每个案例的核心逻辑相同:模型使用一种与语言无关的表示方式,识别出自己正在被问及“small”的反义词。这会触发“antonym”(反义词)特征,这些特征通过影响注意力机制(对应图中的虚线),实现从“small”到“large”的映射。与此同时,“open-quote-in-language-X”(X语言中使用引号)特征会追踪当前语言,并激活与该语言相匹配的输出特征,以做出正确的预测(例如,“big”-in-Chinese——中文中的“大”)。然而,我们的英文归因图表明,在某种有意义的意义上,英语在机制上享有优先地位,被视为模型的”默认”语言。
我们可以将这一计算过程分为三个部分:操作(即反义词)、操作数(即“小”),以及语言。在接下来的章节中,我们将提供三个实验,证明这三者可以被独立干预。总结如下:
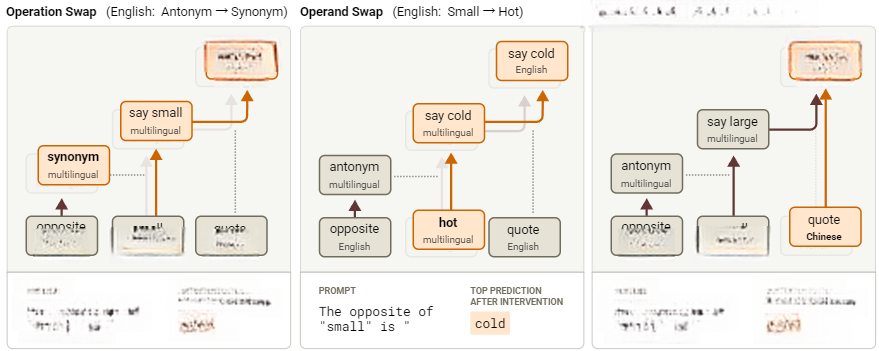
图18:我们将进行的三类干预实验的概述,分别对操作、操作数和语言进行干预
最后,我们将通过展示多语言特征的广泛存在性来结束本节,这些特征广泛分布于模型中,随着模型规模增大,其在表征中的比重持续增加。
5.1 编辑操作类型:反义转同义
我们现在将展示一组比上述总结更为详细的干预实验,首先聚焦“反义转同义”的操作调整。
在模型中间层的末端标记处,聚集着反义特征,这些特征在模型预测最近形容词的反义词或对立面之前被激活。我们在相同的模型深度上找到了类似的同义词特征集合。这些可以理解为同义词和反义词的功能向量。尽管同义词和反义词向量在功能上是对立的,但有趣的是,所有同义词和反义词编码器向量之间的成对内积都是正的,而解码器向量的最小内积仅略为负值。在相同的模型深度下,针对英文提示词“A synonym of ‘small’ is”(“‘small’的同义词是”)。
为了验证我们对这些特征的解释,我们对每种语言中的反义词特征超节点进行了负向干预,并替换成同义词特征超节点。尽管这两组特征均源自英文提示词(例如“A synonym of ‘small’ is”),但干预后模型仍能输出适配目标语言的同义词,这证实了回路中的运算模块具备语言普适性。
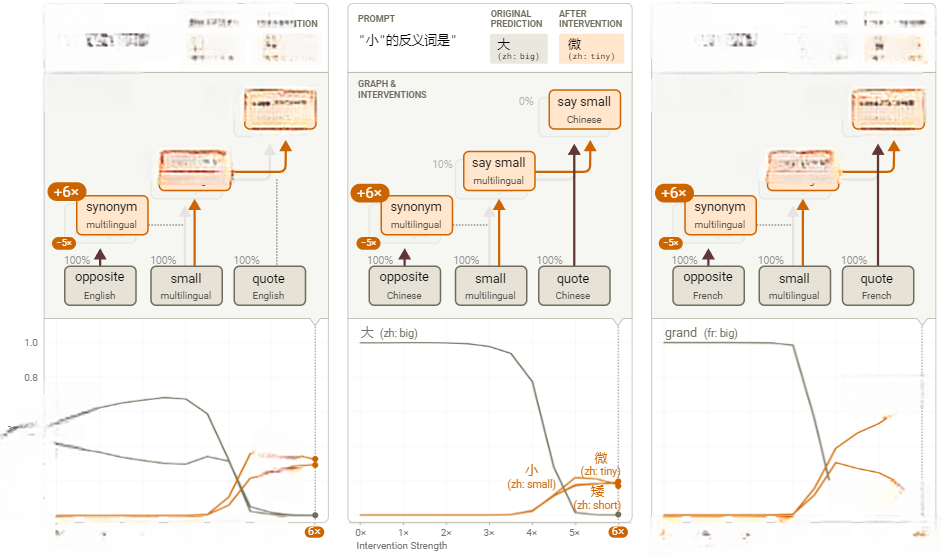
图19:对操作进行干预的实验,展示了在三种不同语言输入情况下,将反义词特征替换为同义词特征的结果
干预实验中,除了模型能够正确预测出合适的同义词外,下游的“say ‘big’”节点的激活被显著抑制(通过百分比变化显示),而上游节点的激活保持不变。这一现象表明,干预仅影响了下游的输出选择,而上游的任务类型(如“寻找同义词/反义词”的决策)未受影响。需注意的是,干预虽需超常强度(需6倍同义词提示词的激活量),但生效临界值在不同语言间高度一致(约4倍强度)。
5.2 修改操作数:从“小”到“热”
在第二项干预中,操作数由“小”(“small”)改为“热”(“hot”)。观察发现,在“small”这个词的位置上,存在一组早期特征,似乎捕捉了该词的“尺寸属性(size facet)”。我们通过将英文提示词中的“small”替换为“hot”,发现类似的特征会捕捉“hot”一词的“热相关属性(heat-related facet)”。许多特征仅在“hot”和“small”这两个词上被激活。我们选择这些节点是因为它们具有最高的“图影响”,表明它们在预测合适的反义词时具有最大的因果作用。
与之前的实验类似,为了验证这一解释,我们替换了“small”的尺寸特征为“hot”的温度特征(作用于提示词中的“small”/“petit”/“小”token)。尽管温度特征源自英文提示词,但模型仍能输出对应语言中“hot”的反义词(如“cold”)。这再次证实,操作数处理机制具备跨语言普适性。
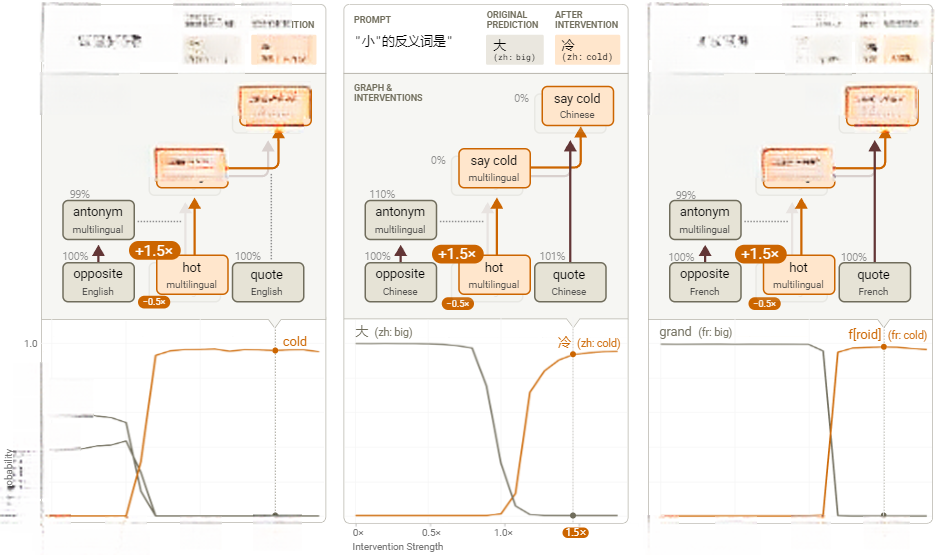
图20: 操作数干预实验——在三种不同语言输入中将“small”特征替换为“hot”特征
5.3 修改输出语言
在我们的最终干预实验中,我们将改变输入的语言。
在模型的前几层,在最终token位置上,存在一组特征,用于指示当前上下文所使用的语言。这些特征包括特定语言的引号特征(equivariant open-quote-in-language-X features)和文档开头特征(beginning-of-document-in-language-Y features),例如法语、中文等语言特有的标识符。我们将每种语言的这组语言检测特征收集到一个超节点中。
如下图所示,通过替换早期语言检测特征将原始语言特征组替换为其他语言对应特征组,即可改变输出语言。这验证了我们能在保持运算逻辑的同时修改语言参数。

图20: 操作数干预实验——在三种不同语言输入中将“small”特征替换为“hot”特征
5.4 法语回路细节解析
上述展示的回路图经过了高度简化。为了更深入理解,我们选择以法语回路为例进行更为详细的探讨。需要注意的是,这里展示的法语回路仍然是简化的版本,若需要查看更原始的数据或图表,请参见标题中的链接。
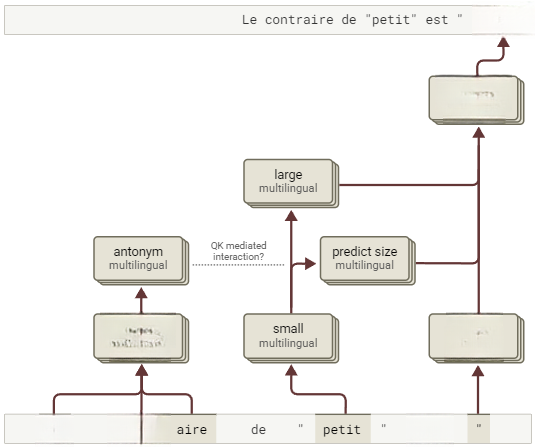
图22:对于法语提示词,这里展示了一个稍微更详细的归因图,尽管仍然大幅简化。请注意,其中一个最有趣的交互似乎是一个由查询-键(QK)介导的效果,在我们当前的方法中不可见(但已在干预实验中得到验证)(交互式图表)。
除了上述交互,还有一些有趣的现象:
-
我们观察到多标记词(如法语中的“contraire”)通过“去标记化”激活了抽象的多语言特征。
-
我们发现了一个名为“predict size”(预测尺寸)的特征组,该特征组在简化图中被省略(因其效果弱于其他特征)。
-
我们还观察到特定语言的引号特征会追踪当前处理的语言,但完整的回路表明模型会从其他词汇中获取语言线索,而不仅依赖显式特征(如引号或标点符号)。
-
这种结构与我们在其他语言中观察到的回路结构大体相似。
这种现象的普遍性如何?根据现有案例分析,计算的关键处理环节,始终依托语言无关节点运行。例如,在下面的三个简单提示词中,尽管输入中没有任何共享的token,但核心语义转换都经由同一组多语言关键节点完成,且该现象在不同语言中普遍存在。
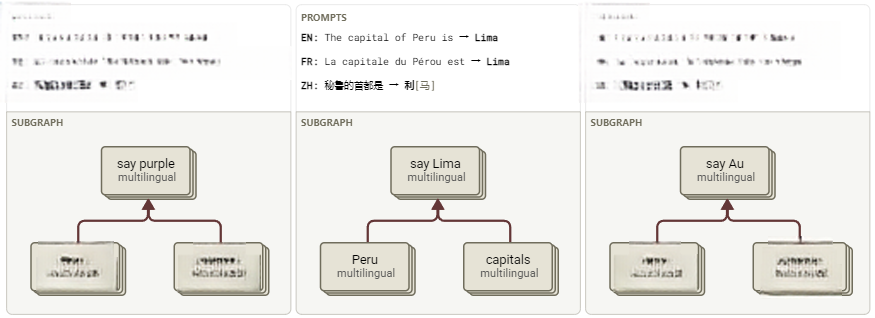
图23:在不同语言的一组翻译提示词中,重要的多语言节点和边。所有显示的特征在每种语言中均处于激活状态。对于每个提示词和语言,通过这些节点的路径占比为10–58%,而它们仅占整体节点的0.8–2.6%(交互式图表)。
基于此设计验证实验量化跨语言泛化程度:测量相同特征在翻译成不同语言的文本上激活的频率。也就是说,如果相同特征在文本的翻译版本上激活,但在无关文本上不激活,即可证明模型构建了跨语言统一表征架构。
为验证此假设,我们收集了一个包含多种主题段落的数据集上的特征激活情况,这些段落有(Claude生成的)法语和中文翻译。对于每个段落及其翻译,我们记录在上下文中任何位置激活的特征集合。对于每组{段落、语言对、模型层},我们计算交集(即在两种语言中均激活的特征集合),并将其除以并集(即在任一语言中激活的特征集合),以测量重叠程度。作为基线,我们将此与相同语言对的无关段落的“交集与并集”测量结果进行比较。
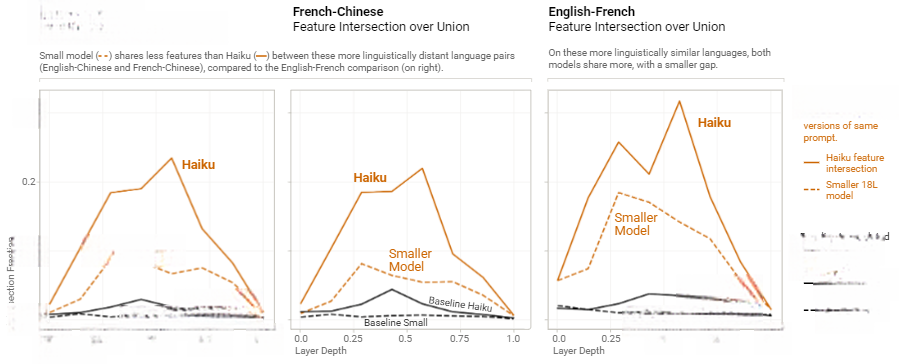
图23:在不同语言的一组翻译提示词中,重要的多语言节点和边。所有显示的特征在每种语言中均处于激活状态。对于每个提示词和语言,通过这些节点的路径占比为10–58%,而它们仅占整体节点的0.8–2.6%(交互式图表)。
这些结果显示,模型开头和结尾的特征具有高度的语言特异性(符合解/重标记化假说[33]),而中间层特征展现跨语言共性。此外值得注意的是,相较于小型模型,Claude 3.5 Haiku表现出更强的泛化能力,特别是在那些不共享字母表的语言对(英语-中文,法语-中文)之间,其泛化改进尤为显著。
5.6 模型是否用英语思考?
随着研究者对模型多语言机制的深入探索,学术界逐渐形成两种对立观点。一方面,许多研究者发现了多语言神经元和特征[22,23,24],以及其他多语言表征的证据[25]。另一方面,Schut 等人提出了模型优先使用英语表征的证据[29],而 Wendler 等人则提供了中间立场的证据[30],即表征是多语言的,但与英语最为一致。
我们应如何看待这些相互矛盾的证据?
我们观察到Claude 3.5 Haiku确实运用了真正的多语言特征,尤其在模型中间层表现显著。然而,在某些重要的机制上,英语仍然占据主导地位。例如,多语言特征对相应的英语输出节点具有更显著的直接权重,而非英语输出则更多地通过“say-X-in-language-Y”特征进行间接调控。此外,“English-quote”(英语引号)特征似乎表现出一种双向调控效应:它们抑制那些本身会抑制英语中的“large”但却促进其他语言中“large”的特征(例如,这个English-quote特征最强的负向边连接到一个特征,该特征增强罗曼语族语言(如法语)中的“large”,同时削弱其他语言(尤其是英语)中的“large”)。这些机制共同构建出以英语为默认基准的多语言表征体系。
小结
通过归因图这一创新方法,Anthropic团队首次系统性地追踪了Claude 3.5 Haiku等大语言模型从输入到输出的内部计算路径。在理解了方法的背景、原理及其局限后。我们可以回到文章开头回答那三个问题,大语言模型在完成推理任务时,既能推理,又会走捷径;在完成作诗任务时,在大语言模型内部发现了明显的规划回路;而大语言模型虽然对英语有着“天然”的亲近,但它有自己的原生语言。这些发现标志着我们正在从观察模型“做什么”转向理解它“如何做”,为人工智能的可解释性、安全性与可控性研究提供了更具结构性的分析路径。
大模型可解释性读书会读书会
集智俱乐部联合上海交通大学副教授张拳石、阿里云大模型可解释性团队负责人沈旭、彩云科技首席科学家肖达、北京师范大学硕士生杨明哲和浙江大学博士生姚云志共同发起。本读书会旨在突破大模型“黑箱”困境,尝试从以下四个视角梳理大语言模型可解释性的科学方法论:
自下而上:Transformer circuit 为什么有效?
自上而下:神经网络的精细决策逻辑和性能根因是否可以被严谨、清晰地解释清楚?
复杂科学:渗流相变、涌现、自组织等复杂科学理论如何理解大模型的推理与学习能力?
系统工程:如何拥抱不确定性,在具体的业界实践中创造价值?
五位发起人老师会带领大家研读领域前沿论文,现诚邀对此话题感兴趣的朋友,一起共创、共建、共享「大模型可解释性」主题社区,通过互相的交流与碰撞,促进我们更深入的理解以上问题。无论您是致力于突破AI可解释性理论瓶颈的研究者,探索复杂系统与智能本质的交叉学科探索者,还是追求模型安全可信的工程实践者,诚邀您共同参与这场揭开大模型“黑箱”的思想盛宴。
读书会计划于2025年6月19日启动,每周四晚19:30-21:30,预计持续分享10周左右。
详情请见:
1.
2.
3.
4.
5.
6.
