热点推荐
热门图文

中国和西班牙研究人员发表的一篇新论文发现,即使是像GPT-4.1这样的先进多模态人工智能模型,也难以从模拟时钟图像中识别时间。时钟中细微的视觉变化都可能导致严重的解读错误,而微调也只对熟悉的示例有效。这一结果引发了人们对这些模型在现实世界任务中处理不熟悉图像时的可靠性的担忧。
当人类对某个领域(例如重力或其他基本物理原理)有了足够深入的理解时,我们就能超越具体的例子,掌握其背后的抽象概念。这使我们能够创造性地跨情境运用这些知识,并通过识别实际应用中的原理来识别新的实例,即使是那些我们从未见过的实例。
当一个领域足够重要时,我们甚至可能在它并不存在的地方感知到它,就像空想性错视一样,其驱动力在于无法识别真实实例的高昂代价。这种模式识别的生存机制如此强大,以至于它甚至促使我们在没有模式的地方寻找更广泛的模式。
一个领域在我们心中灌输得越早、越反复,它的基础就越深,并且会持续一生;我们在儿童时期接触到的最早的视觉数据集之一就是教学时钟,其中印刷材料或交互式模拟时钟被用来教我们如何看时间:

帮助孩子学习认识时间的教具
尽管手表设计时尚的变化有时会给我们带来挑战,但这种早期领域掌握的弹性令人印象深刻,即使面对复杂或“古怪”的设计选择,我们也能辨别模拟钟面:

高级定制腕表中的一些挑战性面孔
人类不需要成千上万的例子来了解时钟的工作原理;一旦掌握了基本概念,我们几乎可以识别任何形式,即使是扭曲或抽象的形式。
相比之下,人工智能模型在完成这项任务时面临的困难凸显了一个更深层次的问题:它们的表面实力可能更多地取决于大量的曝光,而不是理解。
在近期对大型模型的研究中,表面表现与真正“理解”之间的矛盾反复浮现。上个月,浙江大学和西湖大学在一篇题为《博士级LLM真正掌握初等加法吗?》(非本文重点)的论文中重新阐述了这个问题,并得出结论:
“尽管基准令人印象深刻,但模型显示出对模式匹配而非真正理解的严重依赖,这由符号表示的失败和基本属性的违反所证明。
明确的规则规定会损害性能,这表明存在固有的架构限制。这些见解揭示了评估方面的差距,并强调了对能够进行超越模式识别的真正数学推理的架构的需求。”
本周,这个问题再次被提出,由南京航空航天大学和西班牙马德里理工大学合作完成。这篇题为《多模态大型语言模型(MLLM)真的学会了在模拟时钟上报时吗?》的新论文探讨了多模态模型对报时理解的程度。
尽管论文中仅详细介绍了研究进展,但研究人员的初步测试表明,OpenAI的GPT-4.1多模态语言模型难以从多种时钟图像中正确读取时间,即使在简单的情况下也经常给出错误的答案。
这表明模型的训练数据可能存在缺口,因此需要一个更均衡的数据集,以测试模型是否能够真正学习其背后的概念。因此,作者整理了一个模拟时钟的合成数据集,均匀地覆盖了所有可能的时间,并避免了互联网图像中常见的偏差:
AI为何读不懂钟表?模拟时钟暴露的认知短板与AI进化隐忧-AI.x社区

研究人员合成模拟时钟数据集中的一个示例,用于在新研究中微调GPT模型
在对新数据集进行微调之前,GPT-4.1一直无法读取这些时钟。然而,在接触了新数据集一段时间后,它的表现有所改善——但前提是新图像与它之前见过的图像相似。
当时钟的形状或指针的样式发生变化时,准确度会急剧下降;即使是很小的调整,例如更细的指针或箭头(下图最右边),也足以使其偏离目标;此外,GPT-4.1还难以解读达利风格的“融化时钟”:
AI为何读不懂钟表?模拟时钟暴露的认知短板与AI进化隐忧-AI.x社区
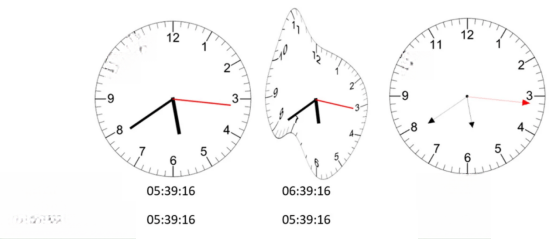
标准设计的时钟图像(左)、变形的时钟图像(中)和修改后的指针图像(右),以及GPT-4.1微调前后返回的时间
作者推断,当前的模型(例如GPT-4.1)可能主要通过视觉模式匹配来学习读钟,而不是通过任何更深层次的时间概念,并断言:
“当时钟变形或指针变细并带有箭头时,GPT-4.1就会失效。在150个随机时间上进行的时间估计中,初始时钟的平均绝对误差(MAE)为232.48秒,形状变形时为1380.69秒,指针改变时为3726.93秒。
这些结果表明,MLLM并没有学会看时间,而是记住了模式。”
大多数训练数据集依赖于抓取的网络图像,这些图像往往会重复特定的时间——尤其是10:10,这是手表广告中流行的设置:

从新论文中,我们可以看到模拟时钟图像中“十点十分”时间的流行情况
由于所描绘的时间范围有限,模型可能只能看到狭窄范围的时钟配置,从而限制了其超越这些重复模式进行概括的能力。
关于模型为何无法正确解释时钟扭曲的问题,论文指出:
“尽管GPT-4.1在标准时钟图像上表现非常出色,但令人惊讶的是,通过使时钟指针变细并添加箭头来修改时钟指针会导致其准确性显著下降。
直观地看,人们可能会认为视觉上更复杂的变化——扭曲的表盘——会对性能产生更大的影响,但这种修改似乎影响相对较小。
这就引出了一个问题:MLLM如何解读时钟,以及它们为什么会失败?一种可能性是,较细的指针会削弱模型感知方向的能力,从而削弱其对空间方向的理解。
或者,当模型尝试将时针、分针和秒针组合成准确的时间读数时,可能会有其他因素造成混淆。”
作者认为,找出这些失败的根本原因是推进多模态模型的关键:如果问题在于模型如何感知空间方向,微调可能会提供一个简单的解决方案;但如果问题源于整合多种视觉线索的更大困难,那么这表明这些系统在处理信息的方式上存在更根本的弱点。
为了测试模型的缺陷能否通过实践克服,GPT-4.1在上述综合合成数据集上进行了微调。在进行微调之前,它的预测结果非常分散,所有类型的钟面都存在显著的误差。在对数据集进行微调之后,其在标准钟面上的准确率显著提高,而在变形钟面上的准确率则有所提升(但幅度较小)。
然而,指针经过修改的时钟,例如指针变得更细或变成箭头状,仍然会产生很大的误差。
出现了两种截然不同的故障模式:在正常和变形的时钟上,模型通常会错误判断指针的方向;但在指针样式改变的时钟上,它经常混淆每根指针的功能,将小时误认为分钟,或将分钟误认为秒。

这张对比图展示了模型最初的弱点以及通过微调实现的部分改进,图中显示了150个随机选择的时钟的预测时间与实际时间(以秒为单位)。左侧是微调之前,GPT-4.1的预测结果比较分散,并且通常与正确值相差甚远,红色对角线表示正确值。右侧是在平衡合成数据集上进行微调之后,预测结果与真实值更加接近,尽管仍然存在一些误差。
这表明该模型已经学会将指针的厚度等视觉特征与特定角色联系起来,并且在这些线索发生变化时会遇到困难。
对不熟悉的设计的有限改进进一步引发了人们的怀疑:这种模型是否学习了报时的抽象概念,或者仅仅是改进了其模式匹配。
因此,尽管微调提高了GPT-4.1在传统模拟时钟上的性能,但它对指针较细或箭头形状的时钟的影响要小得多,这增加了一种可能性,即该模型的失败不是源于抽象推理,而是源于对哪根指针是哪根指针的混淆。
为了测试消除这种混淆后准确率是否会提高,研究人员对模型对“修改后的指针”数据集的预测进行了新的分析。输出结果分为两组:GPT-4.1正确识别时针、分针和秒针的情况;以及未能正确识别的情况。
在微调之前和之后,对预测的平均绝对误差(MAE)进行评估,并将结果与标准时钟的结果进行比较;还使用表盘位置作为基线测量了每个指针的角度误差:

修改后的指针数据集中,微调前后有和没有指针类型混淆的时钟的误差比较
混淆时钟指针的角色会导致最大的误差。当GPT-4.1将时针误认为分针或将分针误认为时针时,最终的时间估算结果往往相差甚远。相比之下,错误判断正确识别的指针方向所导致的误差较小。在三个指针中,时针在微调前的角度误差最大,而秒针的角度误差最小。

在修改后的指针数据集中,经过微调之前和之后,对于有和没有指针角色混淆的预测,指针类型的角度误差。
为了仅关注方向性误差,分析仅限于模型正确识别每个指针功能的案例。如果该模型已经内化了一般的报时概念,那么它在这些示例上的表现应该与在标准时钟上的准确度相当。然而,它并没有,准确度仍然明显下降。
为了检验指针形状是否会影响模型的方向感,研究人员进行了第二项实验:创建了两个新的数据集,每个数据集包含60个只有时针的合成时钟,指向不同的分钟刻度。一组数据集使用原始指针设计,另一组数据集使用修改后的版本。要求模型说出指针指向的刻度标记的名称。
结果表明,修改后的指针识别准确率略有下降,但不足以解释模型的整体缺陷。即使在之前表现良好的任务中,一个不熟悉的视觉特征似乎也足以扰乱模型的整体解读。

GPT-4.1在标准、扭曲和修改后的时钟上进行微调前后的性能,突出了不均衡的收益和持续存在的弱点。
虽然这篇论文的重点乍一看似乎无关紧要,但视觉语言模型能否学会以100%的准确率读取模拟时钟,这一点其实也并不重要。这篇文章的真正意义在于它聚焦于一个更深层次的反复出现的问题:用更多(也更多样化)的数据来填充模型,是否能够获得人类通过抽象和泛化获得的那种领域理解;或者,唯一可行的途径是否是向该领域注入足够多的样本,以便在推理过程中预测所有可能的变化。
这两种方式都会引发人们对当前架构真正学习能力的怀疑。
