
作者:李媛媛
本文约2300字,建议阅读8分钟
理解这些,就能明白AI是怎么“长大”的。
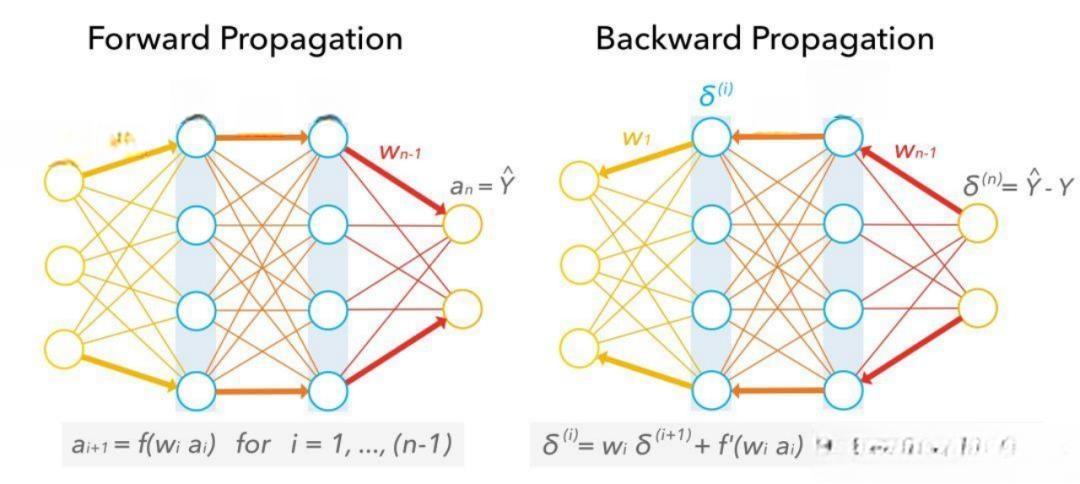
一、前向传播:数据怎样在神经网络里“流动”
想象神经网络像一个大迷宫,数据从入口(输入层)进去,经过弯弯曲曲的通道(隐藏层),最后从出口(输出层)出来。
输入层:
就是迷宫的入口,接收原始数据。比如:
- 图片:每个像素是一个数字,告诉网络这个位置的亮度或颜色。
- 声音:波形图上的每个点是一个数字,记录声音的高低变化。
数据需要“打扮”一下才能进迷宫:
- 归一化:把数据缩放到0到1之间,像把大象装进冰箱前先缩小。
- 编码:把文字变成电脑能懂的数字,比如“猫”变成[0.1, 0.5, 0.3,...]。
隐藏层:
迷宫里最复杂的部分,有很多“房间”(神经元)。
每个神经元做三件事:
- 收集信息:把前面所有神经元的输出加起来,像收集情报。
- 加权求和:给每个信息乘一个“重要系数”(权重),再加一个“基准值”(偏置),公式是:总和=(输入1×权重1)+(输入2×权重2)+...+偏置。
- 激活函数:给总和“变形”,让网络能学复杂东西:
- ReLU:把负数变0,正数不变,像“剪掉”负值。
- Sigmoid:把数压到0到1之间,像概率。
- Tanh:把数压到-1到1之间,像“放大缩小”。
输出层:
迷宫的出口,给出最终答案。
- 分类任务:用Softmax,把数字变成概率,比如“这张图80%是猫,20%是狗”。
- 回归任务:直接输出数字,比如“预测房价是120万”。
举个栗子:
输入一张猫的图片→ 卷积层找边缘 → 池化层缩小图片 → 再卷积层找猫耳朵 → 全连接层判断“是猫”。
二、后向传播:网络怎样“自我学习”
前向传播是“做题”,后向传播是“改错”。
计算“错题分”(损失函数):
- 均方误差(MSE):预测值和真实值的平均差距,适合回归任务。
- 交叉熵损失:预测概率和真实标签的差距,适合分类任务。
找“错题原因”(梯度计算):
用链式法则,像剥洋葱一样层层找原因。
从输出层开始,问:“这个结果错了,是因为哪个参数没调好?”
反向传播误差,告诉每个神经元“你该改多少”。
改“错题”(参数更新):
用优化算法,比如梯度下降:
- 想象在山顶放小球,小球沿着最陡的路(梯度)滚下山,直到找到最低点(最优解)。
- 学习率:小球滚的速度,太大可能跳过最低点,太小下得慢。
常用优化器:
- SGD:基础款,但容易卡在沟里。
- Adam:结合动量和历史信息,像自动驾驶调整方向。
- RMSProp:平衡历史梯度,适合复杂地形。
三、训练循环:像教孩子反复练习
准备数据:分训练集(练习题)、验证集(模拟考)、测试集(期末考)。
小批量学习:把数据分成小份(batch),像一次做10道题,改完再做10道。
重复四步:
- 前向传播:做题,算预测值。
- 算损失:对答案,看错多少。
- 后向传播:改错,找原因。
- 更新参数:调整知识,记住正确解法。
直到考好:达到预设次数或精度要求。
训练小技巧:
- 学习率衰减:开始学快点,后来学慢点,像先快跑再散步。
- 正则化:L2正则像“别偏科”,Dropout像“随机请假”,防止死记硬背。
- 早停法:模拟考成绩不再进步就停,防止过拟合。
四、实际应用:神经网络能干啥?
计算机视觉:
- 图像分类:ResNet能认上千种东西。
- 目标检测:YOLO能找到图里的所有物体。
- 人脸识别:刷脸支付、手机解锁。
自然语言处理:
- 机器翻译:Transformer让翻译更流畅。
- 文本分类:BERT能判断邮件是不是垃圾。
- 语音合成:WaveNet能生成像真人的声音。
强化学习:
- 游戏AI:AlphaGo打败人类棋手。
- 机器人控制:让机器人学走路、抓东西。
挑战:
- 过拟合:只会做练习题,考试不会→ 多做题、正则化。
- 欠拟合:连练习题都做不好→ 加深网络、换老师。
- 梯度消失/爆炸:网络太深,信号传不下去 → 残差连接、梯度裁剪。
- 数据不平衡:有些题太少→ 复制题、加重错题分。
五、未来趋势:神经网络会变得更牛吗?
模型更深:ResNet-152有上百层,像超级高楼。
自动化设计:神经网络自己设计自己,像AI建筑师。
训练更快:用TPU/GPU加速,像用超级计算机做题。
交叉领域:
- 量子神经网络:结合量子力学,可能更快。
- 脑机接口:用神经网络读脑电波,控制机器。
硬件升级:
- 专用芯片:TPU、NPU,专门做神经网络计算。
- 神经拟态芯片:模仿人脑结构,可能更高效。
前向传播和后向传播就像神经网络的“消化系统”和“免疫系统”,一个负责处理信息,一个负责自我修复。理解这些,就能明白AI是怎么“长大”的。
