大家好,我是程序员寒山。
知识库回答不准确怎么办?
今天我们再和大家分享一个Excel格式的肿瘤医生问答系统的数据,如何通过结构化提高问答准确率,并使用Python程序自动处理。文中会详细的介绍每个过程,包括python代码怎么写。

一、引言
上期我们讲了RAG知识库的一个菜谱如何结构化,来提高回答准确率的分享,很多粉丝说太麻烦,太复杂。
其实就像前面讲过的,没有那个技术是完美的,要想实现一个效果,背后肯定需要很多努力的,我们现在使用的每项技术背后都有无数的人在为之付出,我们只是站在了巨人的肩膀上,
今天我们对Excel肿瘤医生问答系统数据做结构化,给大家提供一个新的文件格式参考。 同时使用python工具自动处理,详细告诉大家怎么制作工具。
二、数据结构化对 RAG 的意义
随着我们的不断使用,已经感受到数据结构化对于检索增强生成(RAG)是至关重要。 高质量的结构化数据是实现准确、高效问答系统的关键基础。
我们所有的讨论都是以这个为出发点,其实理解这个最好的例子是这样的。
比如:我们上学时候考试最怕什么?最怕题目中有字没有印全,缺少条件,那这个题目就没法解,我记得上高中的时候,经常发生考试过程中有老师进来,某道题目缺个什么什么条件,临时加上。
其实RAG就是这样,内容不全问答不准! 有人可能会说大模型可以纠正,那是它有这个知识的前提,我们的知识库面向的都是私有知识,它不知道的,所以能掰回来多少真的不敢保证。
我们以肿瘤问答的实际应用来看看它的重要性体现:
2.1 提高检索效率
结构化的数据可以使 RAG 系统更快速、准确地定位到与用户问题相关的信息。
例如,在肿瘤问答知识库中,将问题按照肿瘤类型(如肺癌、乳腺癌等)、问题类别(诊断、治疗、预防等)进行结构化分类,当用户提出问题时,RAG 系统能够迅速在相应的结构化数据区域中检索,大大缩短了检索时间。
2.2 增强生成质量
结构化的数据为语言模型提供了更清晰、有序的信息来源,有助于生成更准确、连贯的回答。
例如: 在肿瘤领域,准确的医学知识至关重要,结构化的数据可以确保语言模型在生成回答时,基于可靠且组织良好的知识,减少错误和模糊的回答。
2.3 知识管理与更新
结构化的数据便于对知识库进行管理和更新。
例如:当有新的肿瘤研究成果或治疗方法出现时,可以方便地将其添加到相应的结构化数据类别中,保证知识库的时效性和准确性,进而提升 RAG 系统的性能。
三、数据结构化的方法
在构建肿瘤问答知识库时,提高准确率有很多方法,结构化也有很多方法,这里主要给大家一个参考,非绝对不唯一!
3.1 分类与打标签
根据肿瘤的不同属性(如问题、病例、治疗方法等)对问题和答案进行分类,并添加相应的标签。
例如,对于“胃癌的病症是什么?”这个问题,可以添加“胃癌”、“病例”、“治疗方法”等标签,以便于后续的检索和管理。
3.2 实体抽取与关系建模
从文本数据中抽取关键实体(如肿瘤名称、药物名称、检查项目等),并建立实体之间的关系。
例如,在描述某种肿瘤治疗方案时,明确药物与肿瘤类型之间的关系,这有助于更深入地理解和利用知识。
3.3 层次化结构组织
将知识按照一定的层次结构进行组织。
例如:从宏观的肿瘤领域到具体的肿瘤类型,再到更细的问题类别。这种层次化的结构可以使知识更易于理解和访问。
四、结构化的方向
这些结构化的方法,组合应用可以让知识的准确率提高,提高到什么程度就要看我们的数据做的程度。
分类打标签可以提供到95%的准确率,但是再提高一个百分点就需要付出前面几倍的工作量才可以。这是我们很多技术的一个共性问题:长尾效应。
大家都说从0到1很难是创造,但是从99到100更难是重生。
五、肿瘤问答数据结构化及Python实现
在实际的数据处理中,我们常常会遇到 Excel 格式的数据,为了更好地进行数据结构化和后续的 RAG 应用,需要将其转化为TXT格式的结构化数据并打上标签。

以下是使用 Python 实现这一转化的详细步骤:
5.1 准备工作
首先,确保安装了必要的 Python 环境及库,如 pandas 用于处理 Excel 数据。可以使用 pip install pandas 命令进行安装。csv库用于处理csv格式的数据。
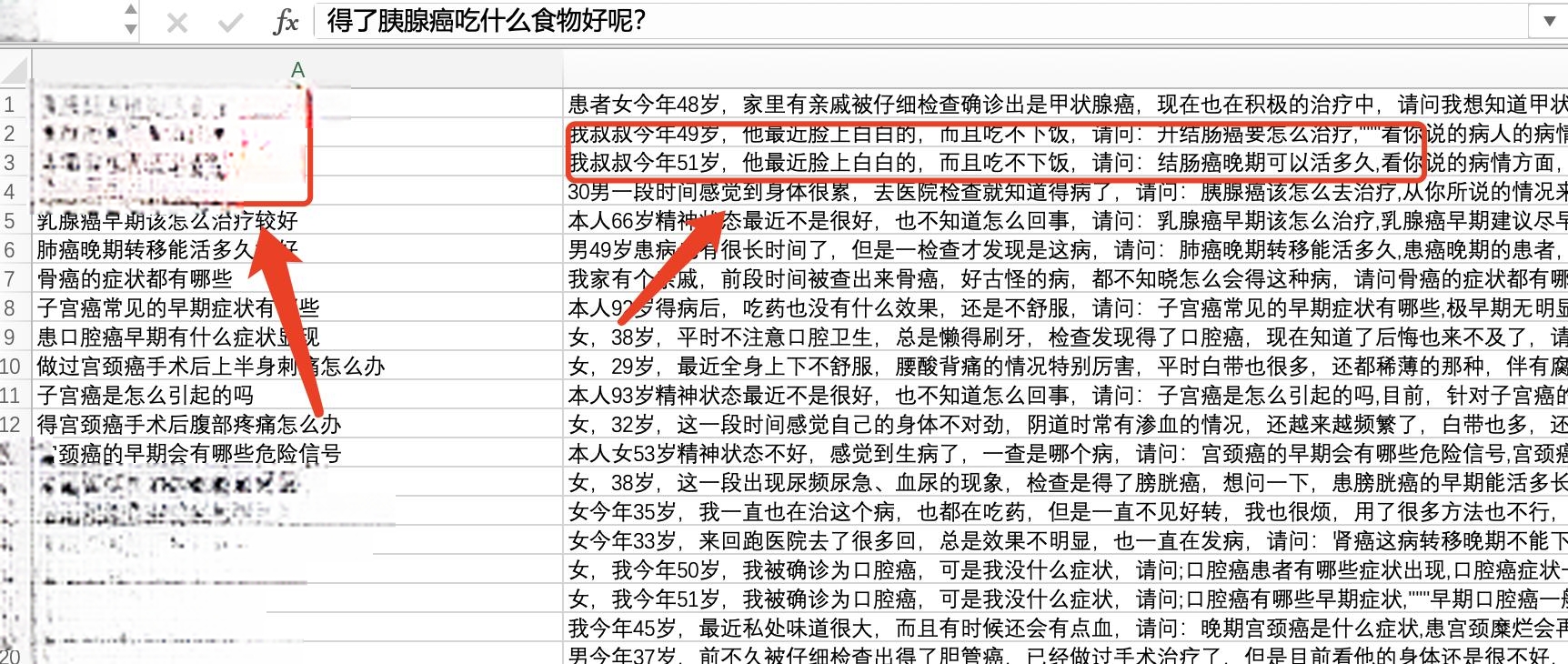
5.2 读取 Excel 数据
使用 pandas 库的 read_excel 函数读取 Excel 文件中的数据。假设我们的 Excel 文件名为 OncologyQA.xlsx,包含“问题”和“病例及治疗方法”两列数据。
import pandas as pd
def excel_to_formatted_txt(excel_file, output_txt_file):
# 读取Excel文件
df = pd.read_excel(excel_file)
5.3 数据处理与结构化打标签
对读取到的数据进行的处理,如去除空值、清洗文本等。然后,按照一定的格式将数据转化为 TXT 结构化数据。
例如,我们可以将每个问题和病例治疗按照“问题:[问题内容] 病例分析:[病例内容]”的格式进行组织。
# 遍历每一行
for index, row in df.iterrows():
# 写入格式化的内容
f.write(f"问题:{row.iloc[0]}\n")
f.write(f"病例分析:{row.iloc[1]}\n")
5.4 数据分段
对数据进行分段处理,使用“####”分段标识符。
# 添加分隔符
f.write("####\n")5.5 保存为 TXT 文件
使用 Python 的文件操作功能,将处理好的 TXT 内容保存为一个 TXT 文件。
# 保存为 TXT 文件
with open(output_txt_file, 'w', encoding='utf-8') as f:
file.write(txt_content)
5.6 完整代码
这是完整的代码,包括csv和excel两种格式的转化功能。
import csv
import pandas as pd
def convert_csv_to_txt(csv_file_path, txt_file_path):
try:
with open(csv_file_path, 'r', encoding='utf-8', newline='') as csvfile, \
open(txt_file_path, 'w', encoding='utf-8') as txtfile:
reader = csv.reader(csvfile)
next(reader) # 跳过标题行
for row in reader:
question = row[0]
case_analysis = row[1]
txtfile.write(f'问题:{question}\n')
txtfile.write(f'病例分析:{case_analysis}\n')
txtfile.write('####\n')
print(f"成功将 {csv_file_path} 转换为 {txt_file_path}")
except FileNotFoundError:
print(f"错误:未找到文件 {csv_file_path}")
except IndexError:
print("错误:CSV 文件中的行格式不符合预期,可能缺少列。")
except Exception as e:
print(f"发生未知错误:{e}")
def excel_to_formatted_txt(excel_file, output_txt_file):
# 读取Excel文件
df = pd.read_excel(excel_file)
# 打开输出文件
with open(output_txt_file, 'w', encoding='utf-8') as f:
# 遍历每一行
for index, row in df.iterrows():
# 写入格式化的内容
f.write(f"问题:{row.iloc[0]}\n")
f.write(f"病例分析:{row.iloc[1]}\n")
# 添加分隔符
f.write("####\n")
if __name__ == "__main__":
excel_file = 'OncologyQA.xlsx'
csv_file = 'OncologyQA.csv'
csv_txt_file = 'csvTotxt.txt'
excle_txt_file = 'excelTotxt1.txt'
convert_csv_to_txt(csv_file, csv_txt_file)
excel_to_formatted_txt(excel_file, excle_txt_file)通过以上步骤,我们成功地将 Excel 格式的肿瘤问答数据转化为了 TXT 结构化数据,为后续的 RAG 应用奠定了良好的基础。
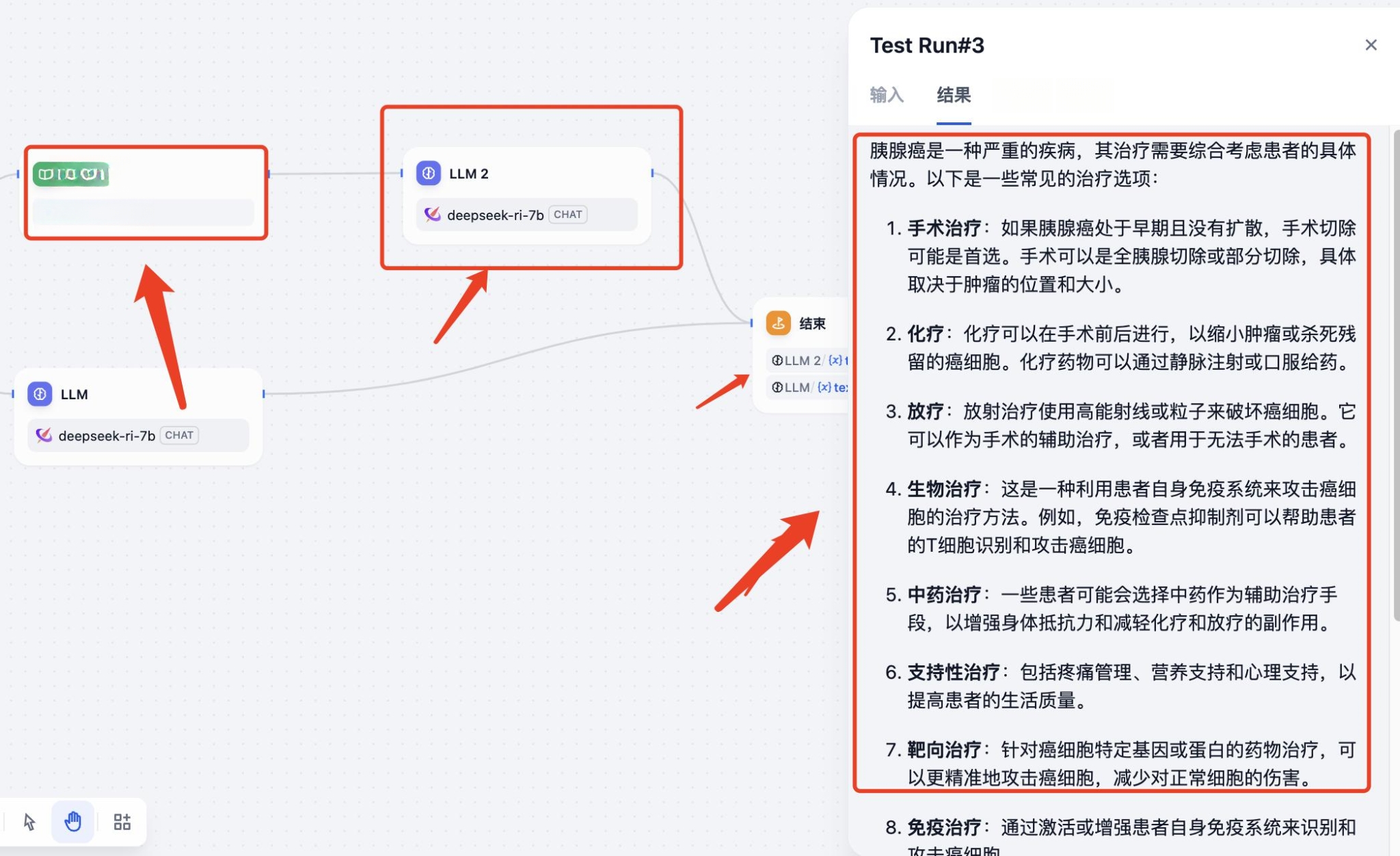
六、测试验证
使用Dify工作流来进行验证。输入我们的问题:“胰腺癌该怎么去治疗?”
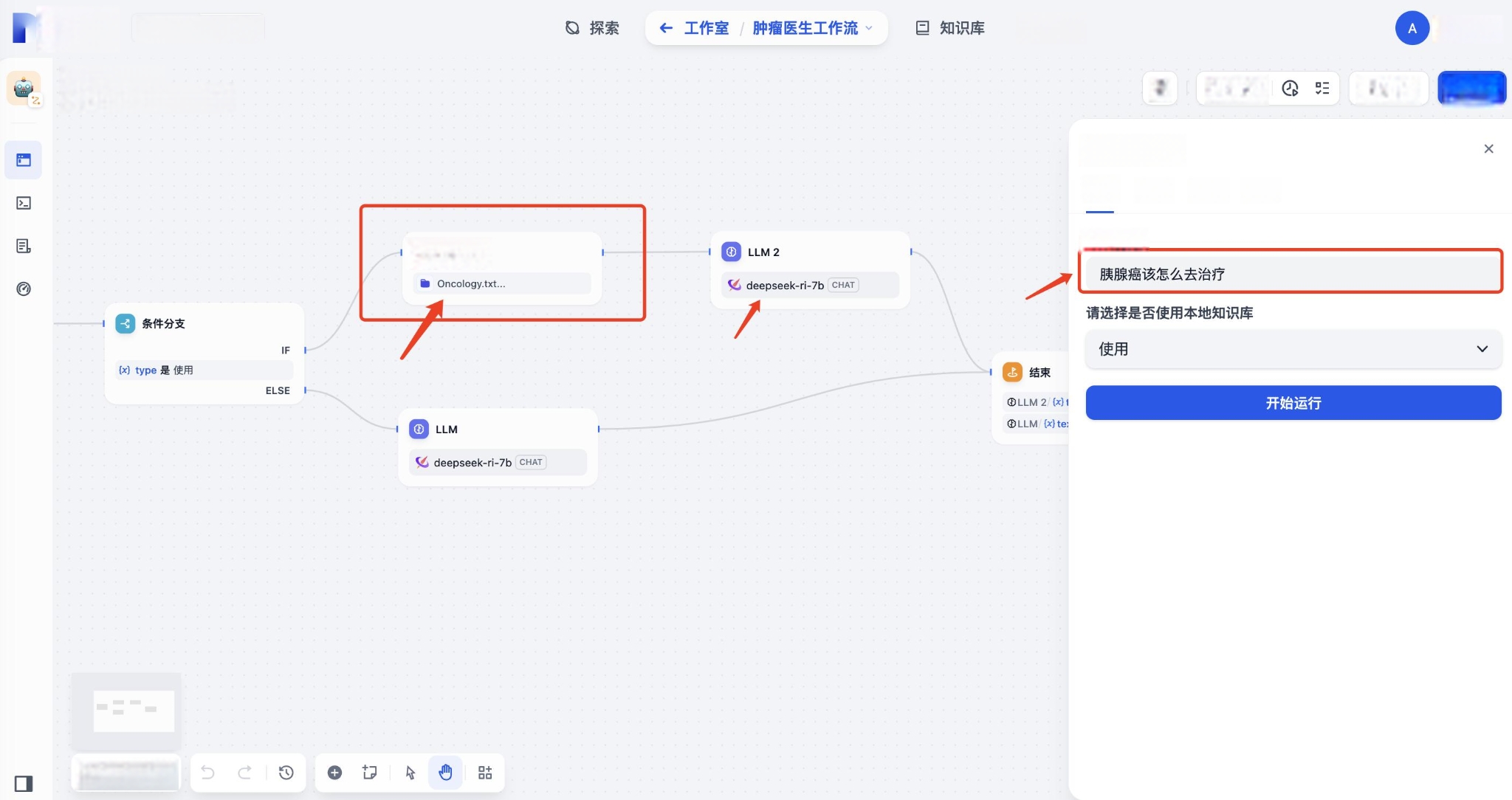
回答的结构:
七、结论
本文以肿瘤问答知识库为例,详细阐述了数据结构化对 RAG 的重要意义,介绍了实用的数据结构化方法,并通过 Python 工具实现了将 Excel 和csv数据转化为 TXT 结构化数据的过程。
合理的数据结构化不仅可以提高 RAG 系统的性能,还能更好地管理和利用知识资源。
在未来更高效、智能的数据结构化方法,将有助于推动 RAG 技术在医疗领域及其他领域的广泛应用。
希望这篇文章能给你带来一些启发和帮助,如果你还有其他问题,请随时留言告诉我。
