丨 共同作者 mmzheng
丨 导语 3月26日约凌晨,OpenAI 发布重大更新GPT4o生图能力,我们联合腾讯新闻频道、以及多篇权威媒体实测内容,为大家整理盘点了OpenAI核心生图发展路线、实测效果下解读它表现优异的典型场景、能力突破、以及细分不足之处,供大家快速了解最新模型能力边界与应用效果。
一、OpenAI 在生图领域的关键里程碑回顾
时间 |
模型/产品 |
核心能力进展 |
2021.1 |
DALL·E 1 |
1. 首次实现文本到图像生成,由 120 亿参数版本的 GPT-3模型经过 4 亿对图像和文本训练而来 |
2021.11 |
GLIDE |
1. 采用引导扩散模型(Guided Diffusion)提高文本控制能力 |
2022年4月 |
DALL·E 2 |
1. 引入 CLIP 先验模型,增强文本-图像对齐 |
2022年11月 |
开放API |
对外开放 DALL·E 的 API 接口,开启商业化运营,根据分辨率的不同,每张收 |
2023年9月 |
DALL·E 3 |
1. DALL-E3与ChatGPT深度集成,允许用户使用 ChatGPT 创建提示并包含更多安全选项 |
2025年3月 |
GPT-4o |
原生多模态图像生成,精准文本渲染,多轮编辑一致性控制等(Now) |
信息来源:《OpenAI GLIDE: AI image generation on a new level》、《Zero-Shot Text-to-Image Generation》、开源证券、国海证券研究所报告
二、GPT-4o 最新版生图能力强项与不足实测解读
1. 精准的文本渲染能力大幅提升
与过去难以生成清晰、恰当位置展示文字的AI模型不同,GPT-4o现在可以准确地将文字嵌入图像中

大段文字输出情况下没有错别字的产生(官方直播演示)
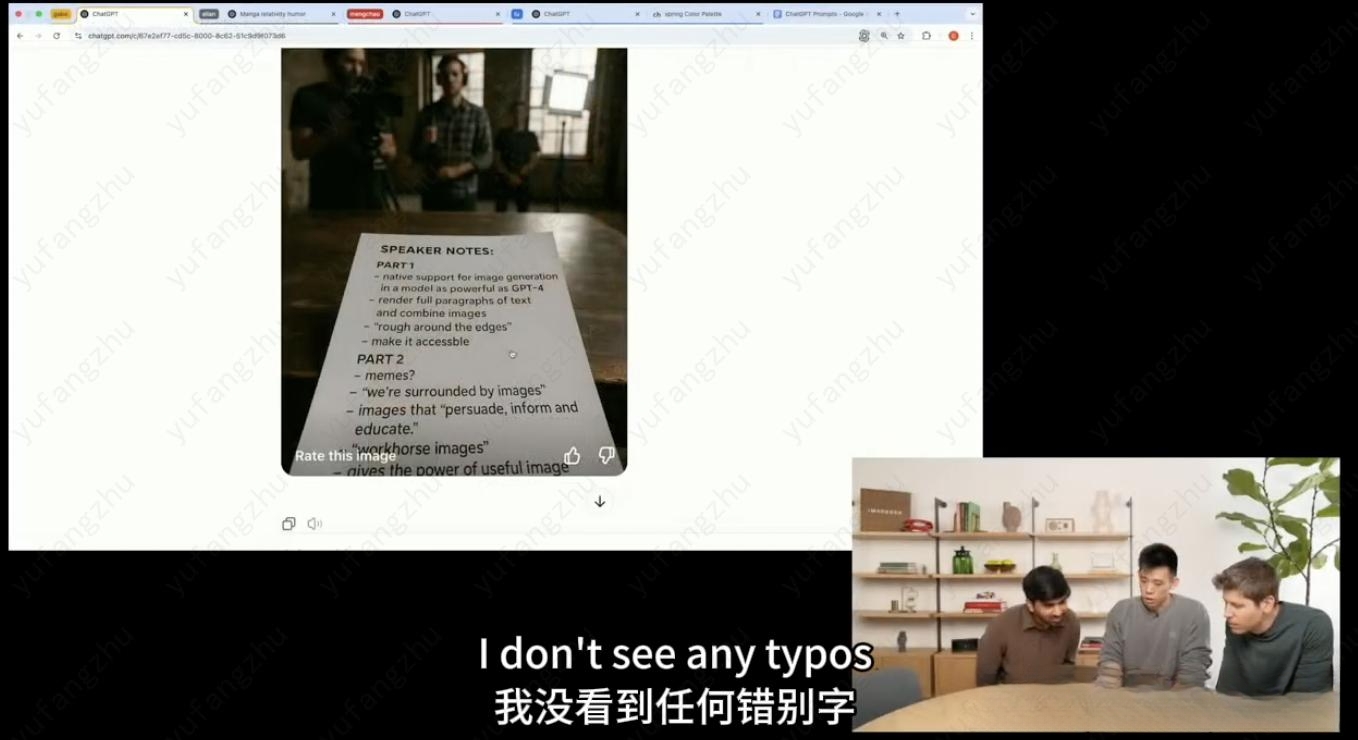
2. 对中文的精准控制能力还不足

3. 图片信息自动整合领域知识
GPT-4o 的绘图,能够从大模型中直接获取到知识,生成与现实世界知识相符的图像,无需用户给出精准专业的内容提示词

4. 复杂场景下依然可能出现领域知识幻觉
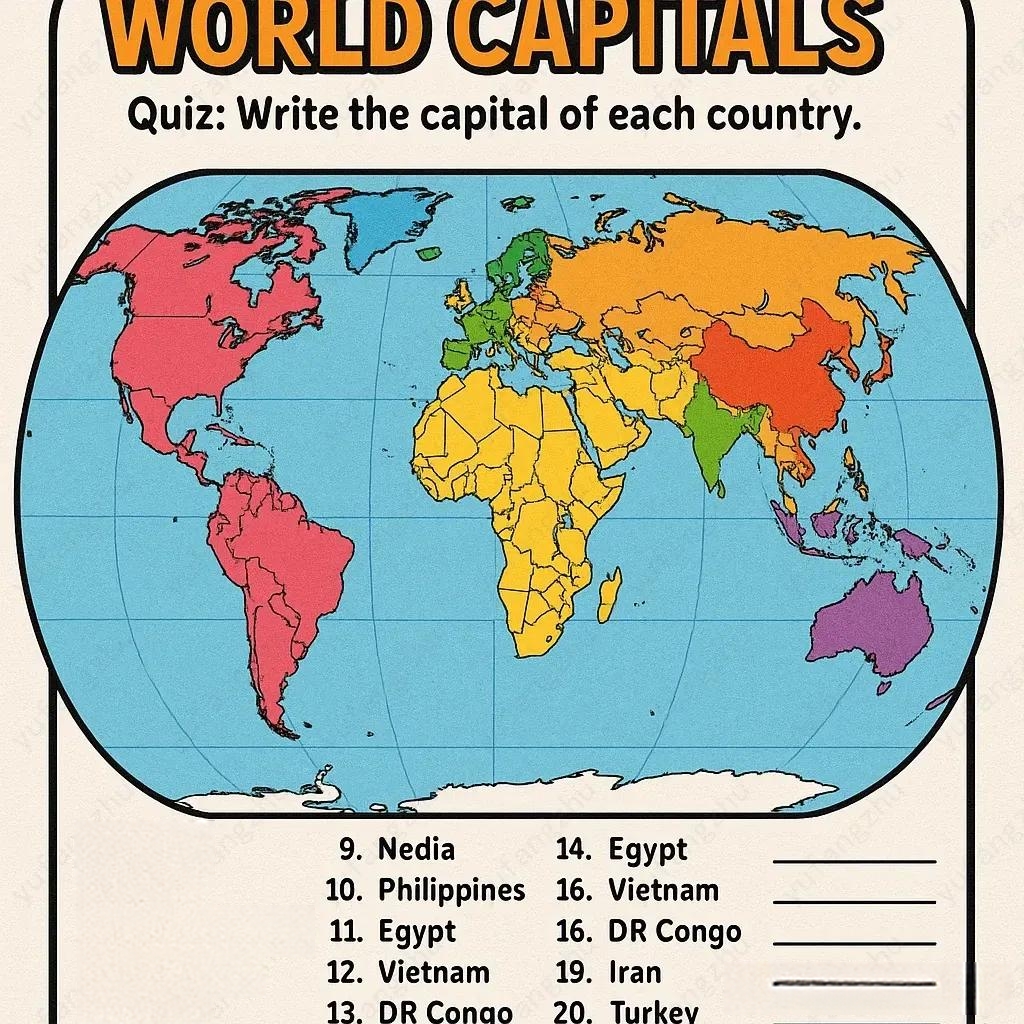
OpenAI 官方主动提出,和其他语言模型一样,图像生成也可能出现错误信息,尤其是在上下文提示不足的情况下。
比如世界地图中,出现两个埃及Egypt,两个越南Vietnam
5. 同一张图可处理 10-20 个不同的对象
GPT‑4o’s image generation follows detailed prompts with attention to detail. While other systems struggle with ~5-8 objects, GPT‑4o can handle up to 10-20 different objects. The tighter binding of objects to their traits and relations allows for better control.
GPT‑4o 的图像生成遵循详细的提示,注重细节。其他系统在处理约 5-8 个对象时会遇到困难,而 GPT‑4o 可以处理 10-20 个不同的对象。对象与其特征和关系的更紧密绑定可以实现更好的控制。

6. 对图片细节的精准控制、多轮对话中前后元素的一致性保持
对话中实现对图片的指向性编辑、且能够让图片元素前后保持一致性,是本次GPT4o图像生成能力从可用到实用的最关键突破

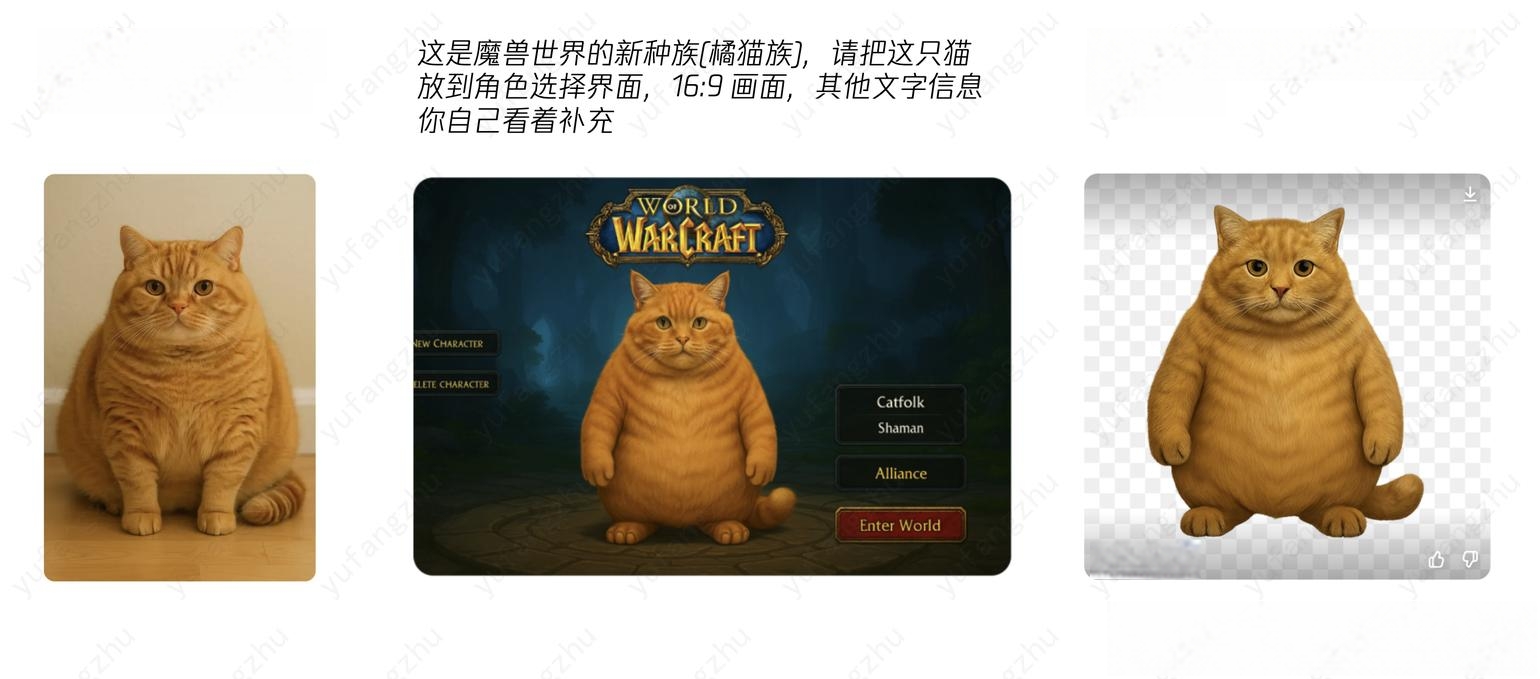
7. 生图的商用、实用价值大幅增强
由于图片一致性的难题突破,从简单素材到完整游戏画面场景的构建成本大幅降低


8. 生成摄影级高质量照片

9. 针对安全类限制内容生成上受限

三、GPT-4o取得突破性进展关键
作为去年推出的多模态模型,GPT-4o最初的定位是成本优化版的旗舰AI模型,具备生成和理解文本、视频、音频和图像等能力。OpenAI表示,此次精调后的版本使普通用户和企业能够更轻松地创建逼真图像、可读文本段落,乃至公司logo和演示幻灯片等。
项目首席研究员Gabriel Goh透露,GPT-4o取得突破性进展的关键,源于人类训练师对模型数据的标注工作——标注了AI生成图像中的错别字、畸形手脚和面部特征等问题。通过“人类反馈强化学习”(RLHF)技术,模型学会了更精准地遵循人类指令,从而生成更准确且实用的图像。
“人类反馈强化学习”是AI公司用来在初步训练后进一步优化模型的常见技术。鉴于OpenAI的AI系统拥有庞大的用户基础——ChatGPT每周拥有超过4亿用户——这些人工训练师的影响力不可忽视。OpenAI表示,参与该优化过程的训练师团队规模略超百人。
