2025年3月1日,中国AI独角兽DeepSeek,在本周以一场技术“核爆”震撼全球——在历时5天的“开源周”收官之际,官方多加了一个彩蛋,独家开源了DeepSeek-V3/R1推理系统概览,首次披露大模型推理系统的核心优化方案及关键财务数据,理论单日成本利润率高达545%,直接刷新了全球AI大模型领域的盈利天花板,今天继续给大家带来最新的解读。

01 DeepSeek独家披露了哪些内容?
今天DeepSeek独家披露了V3/R1在推理系统方面的核心优化策略和技术细节,首次公开了与推理系统相关的关键财务数据,全文篇幅较长,我们一条条来梳理。首先DeepSeek的研发方向十分明确,即实现更大的吞吐量、更低的延迟,这两个目标对于任何 AI 推理系统都极其重要,可以说是推理大模型领域节省成本提高性能的第一性原理。

打个比方,你在使用DeepSeek 的 AI 服务,比如聊天或者生成图片,用户肯定会希望尽快得到结果,你问一句,AI 马上就回答,这是“更低的延迟”,如果遇到很多人都在用 DeepSeek,你希望系统依然流畅,不会因为人多就变慢甚至崩溃,这是“更大的吞吐量”,用在AI大模型的推理和训练上也是如此,为了实现这两个目标,DeepSeek官方披露他们的解决方案——

使用大规模跨节点专家并行(Expert Parallelism / EP)。这种技术在机器学习时代就已经出现,主要是用来提高大规模机器学习模型中的计算效率和资源利用率,如今则是特别适用于MoE混合专家模型,EP的核心思想是将这些专家分配到不同的计算设备(如 GPU)上,使每个设备负责计算其分配的专家子集,从而实现并行计算。
02 大规模跨节点专家并行(Expert Parallelism / EP)
DeepSeek官方解释,由于 DeepSeek-V3 / R1 的专家数量众多,并且每层 256 个专家中仅激活其中 8 个,模型的高度稀疏性导致必须使用很大的 overall batch size,才能给每个专家提供足够的 expert batch size。这里的 batch size 也是指的是深度学习模型中每次训练迭代时用于更新参数的数据样本数量,如果 batch size 规模很大就会占用更多的内存,通俗一点解释,批量处理 (Batch Size) 就像 "打包处理",比如你要寄很多包裹。如果一个一个寄,很慢。但如果把很多包裹打包成一批一起寄,效率就高多了,GPU尤其擅长干这种事情,DS给出两种多卡间并行策略方案:

1.Prefill :可翻译为预填充阶段,采用 EP32(32 个路由专家并行)与 DP32(32 个数据并行),部署单元为 4 节点,每张卡分配 9 个路由专家和 1 个共享专家。目标是快速完成输入编码生成KVCache,适用于计算密集型任务,需要更多专家处理输入特征。
2.Decode :可翻译为解码阶段,将 EP32 和 DP32 扩展至 EP144 和 DP144,部署单元增至 18 节点,每张卡分配 2 个路由专家和 1 个共享专家。目标是加速 token 生成降低延迟,适用于内存密集型任务,依赖 KVCache 和共享专家,路由专家需求减少。
具体来说,当数据输入模型时,系统根据输入数据的特征选择需要激活的专家,由于专家分布在不同设备上,这些设备可以同时处理数据的不同部分,加速整体计算过程,与此同时设备之间还需要传输数据,带来一定的通信开销,于是DeepSeek进一步将EP的设计思路集中在优化通信延迟方面。

03 计算通信重叠
多机多卡的专家并行 (EP) 策略虽然能带来更高的吞吐量和更低的延迟,但也引入了一个新的挑战:巨大的通信开销。想象一下,一个大型工厂,不同的车间(GPU)负责生产不同的零件(专家计算),如果零件生产出来后,需要花费大量时间在车间之间运输 (通信),那么整体生产效率就会大打折扣。 AI 推理系统也是如此,当专家分散在多台机器、多张卡上时,数据需要在它们之间频繁传输,这个传输过程会消耗不少时间,成为系统性能的瓶颈。
为了解决通信开销的问题,DeepSeek 团队采用了 “计算通信重叠” 的策略,核心思想非常简单,就是“一边干活,一边传话”。在等待信息传输 (通信) 的时候,GPU不闲着,而是利用这段时间去做一些计算工作,这样就能把等待时间充分利用起来,减少总的等待时间,提高整体效率。具体实时起来就是“双 batch 重叠” 技术,我们可以用接力赛跑的例子来解释。

Batch (批次) 就像 “接力棒”,代表一批需要处理的数据,例如一批用户请求,计算 (Computation) 就像 “跑步”,代表 GPU 在进行矩阵运算、模型推理等计算工作,通信 (Communication) 就像 “传递接力棒”,代表 GPU 之间在传输数据,例如传递中间计算结果、模型参数等,具体可以与上面的两种多卡间并行策略方案一起打配合:
1.Prefill 阶段的双 batch 重叠:一句话形容就是“你跑你的,我传我的,同时进行”。GPU 正在对第一批数据 (Batch 1) 进行计算,例如进行 attention 计算,生成初始的 hidden states 等,同时,系统也在为第二批数据 (Batch 2) 准备数据传输,例如,从其他 GPU 节点收集需要的专家模型参数,或者将 Batch 2 的输入数据分发到不同的 GPU 上。就像接力赛中,如果传递接力棒的时间能和其他队员跑步的时间重叠,就能更快到达终点。
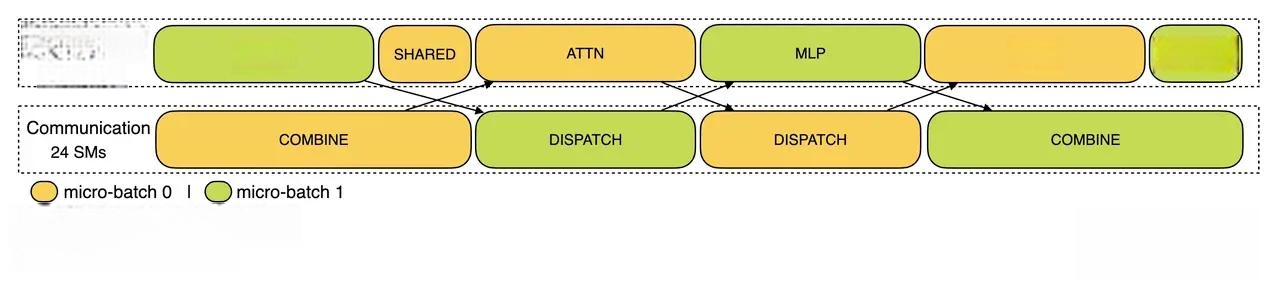
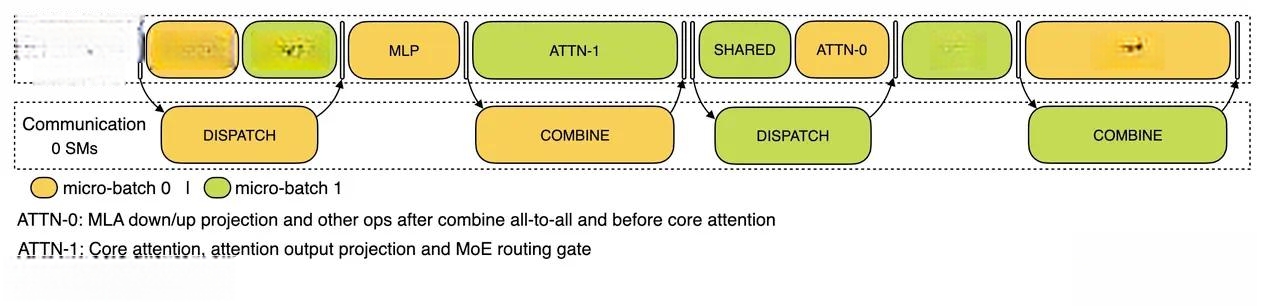
2.Decode 阶段的双 batch 重叠:一句话形容就是“流水线式接力,环环相扣”。由于不同步骤的执行时间差异较大, DeepSeek 将 Attention 细化为 5 个小步骤 (Stage),每个 Stage 负责一部分工作,然后将结果传递给下一个 Stage,让不同的 batch 的计算和通信操作交错进行,比如当 Stage 1 正在处理 Batch 1 的计算时,Stage 2 可能正在进行 Batch 2 的通信, Stage 3 又可能在处理 Batch 1 的另一个计算步骤,以此类推。计算通信重叠在我之前的解读中有更详细的介绍。
04负载均衡
专家并行策略 (EP)的通信开销问题可以通过上面方法解决,但是由于 EP 涉及多个节点,还需要与数据并行 (Data Parallelism / DP) 结合使用,不同的 DP 实例之间可能存在负载不均衡的情况,接下来DeepSeek 团队设计了非常精细的负载均衡策略,针对 Prefill、Decode 和 Expert Parallelism 三个方面进行优化,确保所有 GPU 都能高效运行。
第一个 Prefill Load Balancer 目标是均衡各 GPU 的 core-attention 计算量和 dispatch 发送量。Core-attention 计算量与输入 token 数量相关,token 越多计算量越大,Dispatch 发送量与请求数量相关,请求越多发送量越大,由于不同 DP 实例上的请求个数和长度不同,会导致不同 GPU 上的以下负载不均衡,DeepSeek通过动态分配输入请求,根据 GPU 当前负载和请求的 token 长度,智能地将请求分配到负载较轻的 GPU 上,从而保证 token 数量和请求数量的均匀分布。

第二个 Decode Load Balancer 目标是均衡各 GPU 的 KVCache 占用量(与 core-attention 计算量相关)和 请求数量(dispatch 发送量)。Decode 阶段就是逐个生成输出 token 的阶段,这里Core-attention 计算量还与 KVCache(键值缓存)占用量相关,输入 token 越多 KVCache 越大,计算量也越大,这个阶段不同数据并行(DP)实例上的请求数量和长度仍然不同,所以DeepSeek设计系统根据每个请求的 KVCache 大小以及 GPU 的 KVCache 容量和当前负载,动态分配请求,比如将 KVCache 较小的请求优先分配给已承载较多 KVCache 的 GPU。
第三个 Expert-Parallel Load Balancer 目标是均衡每个 GPU 上的 专家计算量,即之前的开源代码库EPLB。在MoE模型中,某些专家天然地比其他专家接收到更多的 token,称为高负载专家,导致分配到这些专家的 GPU 负载过重,DeepSeek系统会先识别出高负载专家,将它们与低负载专家搭配分配到同一 GPU 上,以平衡整体负载。(参考EP的实例图)
05 DeepSeek的在线统计数据
DeepSeek 公开了线上系统 (DeepSeek V3 和 R1 服务) 的实际运行数据,这些数据使用了 H800 GPU,并采用了与训练一致的精度 (FP8 和 BF16),以保证服务效果,目前DeepSeek线上系统可以根据服务负载动态调整使用的节点数量,白天高负载时使用所有节点部署推理服务,晚上低负载时减少节点用于研究和训练,提高资源利用率。
在最近24 小时内 (2025/02/27 12:00 至 2025/02/28 12:00),DeepSeek V3 和 R1 推理服务 峰值占用 278 个节点,平均占用 226.75 个节点,每个节点 8 个 H800 GPU,峰值 GPU 总数为(278 × 8 = )2224 个 GPU,平均 GPU 总数(226.75 × 8 ≈ )1814 个 GPU。假设 GPU 租赁成本为 2 美金/小时,每日总成本(1814 × 2 × 24 ≈ )87072 美元/天。

Token处理统计中,总输入 Token 数 6080 亿,其中 3420 亿(56.3%)命中磁盘 KV 缓存,显著降低计算负载。输总出 Token 数:1,680 亿,平均输出速度 20-22 token/s,每个输出 Token 平均关联 4989 个缓存 Token;吞吐量统计中,Prefill 阶段输入吞吐约 73.7k token/s,Decode 阶段输出吞吐约 14.8k token/s。
定价模型按 DeepSeek-R1 标准,输入 Token(缓存命中)0.14美元/百万token,输入 Token(未命中)0.55美元/百万token,输出 Token 2.19美元/百万token,理论日收入为 562027 美元,对应 (562027 / 87072≈ )545% 成本利润率。

06 One More Thing
总体来说,这次DeepSeek的One More Thing彩蛋确实非常精彩,用一周时间毫无保留地分享所有关于DeepSeek-V3/R1模型训练推理的各种细节,而且用实际测试数据打脸了一票不看好DS的观众,目前系统在 H800 GPU 上展现了非常高的性能和极强的盈利能力,完全是天花板级别,至此为期一周的DeepSeek解读应该到此就结束了,但是围绕DeepSeek的故事应该还远未结束......(接下来一段时间我可能会休息暂缓AI解读系列的更新)
